9Emerging Biophysics TechniquesAn Outlook of the Future Landscape of Biophysics Tools
Anything found to be true of E. coli must also be true of elephants.
—Jacques Monod, 1954 (from Friedmann, 2004)
Everything that is found to be true for E. coli is only sometimes true for other bacteria, let alone for elephants.
—Charl Moolman (his PhD viva, Friday, March 13, 2015, TU Delft, the Netherlands)
General Idea: Biophysics is a rapidly evolving discipline, and several emerging tools and techniques show significant promise for the future. These include systems biophysics, synthetic biology, and bionanotechnology, increasing applications of biophysics to personalizing healthcare, and biophysics approaches that extend the length scales into the smaller world quantum phenomena and the larger world of populations of organisms, which we discuss here.
9.1 Introduction
There are several core biophysical tools and techniques invented in the twentieth and early twenty-first centuries, which, although experiencing improvements and adaptations subsequent to their inception, have in their primary features at least stood the test of time. However, there are several recently emerging methods that, although less established than the core tools and technologies discussed previously in this book, still offer enormous potential for generating novel biological insight and/or having important applications to society. These emerging tools have largely developed from the crossover of several different scientific disciplines. For example, aspects of systems biology developed largely from computational biology themes have now been adapted to include strong physiology elements that encapsulate several experimental cellular biophysics tools.
Similarly, synthetic biology and bioengineering methods largely grew from chemical engineering concepts in the first instance but now apply multiple biophysics approaches. Developments in diagnostics for healthcare are progressing toward far greater personalization, that is, methods that can be catered toward individual patients, which in particular use biophysics methods.
9.2 Systems Biology and Biophysics: “Systems Biophysics”
Systems biology as a discipline grew from the efforts of the nineteenth-century physiologist Claude Bernard, who developed the founding principles of homeostasis, namely, the phenomenon of an organism’s internal environment being carefully regulated within certain limits, which optimizes its ultimate viability. Ultimately, this regulation of the physiological state involves the interaction between multiple systems in an organism, which we now know can act over multiple different length and time scales.
A key question that systems biology has tried to address is, “what is the correct level of abstraction at which to understand biology?” Reductionist approaches argue that we should be able to understand all biology from a knowledge simply of the molecules present. In a sense, this is quite obviously correct, though equally naïve, since it is not just the molecules that are important but how they interact, the order in which they interact, and the generating of higher order features from these interactions that can in turn feedback to the level of interaction with single molecules. In other words, a more integrationist approach is valuable, and physical scientists know this well from observing emergent behavior in many nonbiological systems, complex higher length scale behavior that is difficult or impossible to predict from a simple knowledge of just the raw composition of a system that can result from the cooperativity between multiple shorter length scale elements that potentially obey relatively simple rules of interaction. As to where to draw the line in terms of what is the most appropriate level of abstraction from which to understand biology, this is still a matter of great debate.
Modern systems biology has now adopted a core computational biology emphasis, resulting in the development of powerful new mathematical methodologies for modeling complex biosystems by often adapting valuable algorithms from the field of systems engineering. However, it is only comparatively recently that these have been coupled to robust biophysical tools and techniques to facilitate the acquisition of far more accurate biomolecular and physiological parameters that are inputted into these models. Arguably, the biggest challenge the modern systems biology field set itself was in matching the often exquisite quality of the modeling approaches with the more challenging quality of the data input, since without having confidence in both any predictions of emergent behavior stemming from the models may be flawed. In this section, we discuss some of the key engineering modeling concepts applied to modeling interactions of components in an extended biological system, and of their coupling with modern biophysical methods, to generate a new field of systems biophysics.
9.2.1 Cellular Biophysics
The founding of systems biophysics really goes back to the early work of Hodgkin and Huxley on the squid axon (see Chapter 1), which can also be seen as the first real example of a methodical cellular biophysics investigation, which coupled biophysical experimental tools in the form of time-resolved electrical measurements on extracted squid nerve cells, with a mathematical modeling approach that incorporated several coupled differential equations to characterize the propagation of the electrical impulse along the nerve cell. A key result in this modeling is the establishment of feedback loops between different components in the system. Such feedback loops are a general feature of systems biology and facilitate systems regulation. For example, in the case of electrical nerve impulse propagation in the squid axon, proteins that form the ion channels in the cell membrane of the axon generate electric current through ion flux that either charges or discharges the electrical capacitance of that cell, which alters the electrical potential across the cell membrane. But similarly, the electrical potential across the cell membrane itself also controls the gating of the ion channel proteins.
Systems biophysics approaches have an enormous potential to bridge the genotype to phenotype gap. Namely, we now have a very good understanding of the composition, type, and number of genes from sequencing approaches in an organism (see Chapter 7) and also separately have several approaches that can act as a metric for the phenotype, or behavior, of a component of a biological process. However, traditionally it has not been easy to correlate the two in general biological processes that have a high degree of complexity. The key issue here is with the high number of interactions between different components of different biological systems.
However, a systems biophysics approach offers the potential to add significant insight here. Systems biophysics on cells incorporates experimental cellular measurements using a range of biophysics tools, with the mathematical modeling of systems biology. A useful modern example is that of chemotaxis, which can operate at the level of populations of several cells, such as in the movement of small multicellular organisms, and at the level of single cells, such as the movement of bacteria.
Chemotaxis is a form of signal transduction, which involves the initial detection of external chemicals by specific cell membrane receptor molecules and complexes of molecules, but which ultimately span several length and time scales. It is a remarkable process that enables whole cells to move ultimately toward a source of food or away from noxious substances. It involves the detection of external chemoattractants and chemorepellents, respectively, that act as ligands to bind either directly to receptors on the cell membrane or to adapter molecules, which then in turn bind to the receptor (which we discussed in the context of an Ising model previously in Chapter 8). Typically, binding results in a conformational change of the receptor that is transformed via several coupled chemical reaction cascades inside the cell, which, by a variety of other complex mechanisms, feed into the motility control system of that cell and result in concerted, directional cellular movement.
In prokaryotes such as bacteria, it is the means by which cells can swim toward abundant food supplies, while in eukaryotes, this process is critical in many systems that rely on concerted, coordinated responses at the level of many cells. Good examples of chemotaxis include the immune response, patterning of cells in neuron development, and the morphogenesis of complex tissues during different stages of early development in an organism.
Cells from the fungus Dictyostelium discoideum display a strong chemotaxis response to cyclic adenosine monophosphate (cAMP), which is mediated through a cell surface receptor complex and G protein–linked signaling pathway. Using fluorescently labeled Cy3-cAMP in combination with single-molecule TIRF imaging and single particle tracking on live cells, researchers were able to both monitor the dynamic localization of ligand-bound receptor clusters and measure the kinetics of ligand binding in the presence of a chemoattractant concentration gradient (Figure 9.1a).
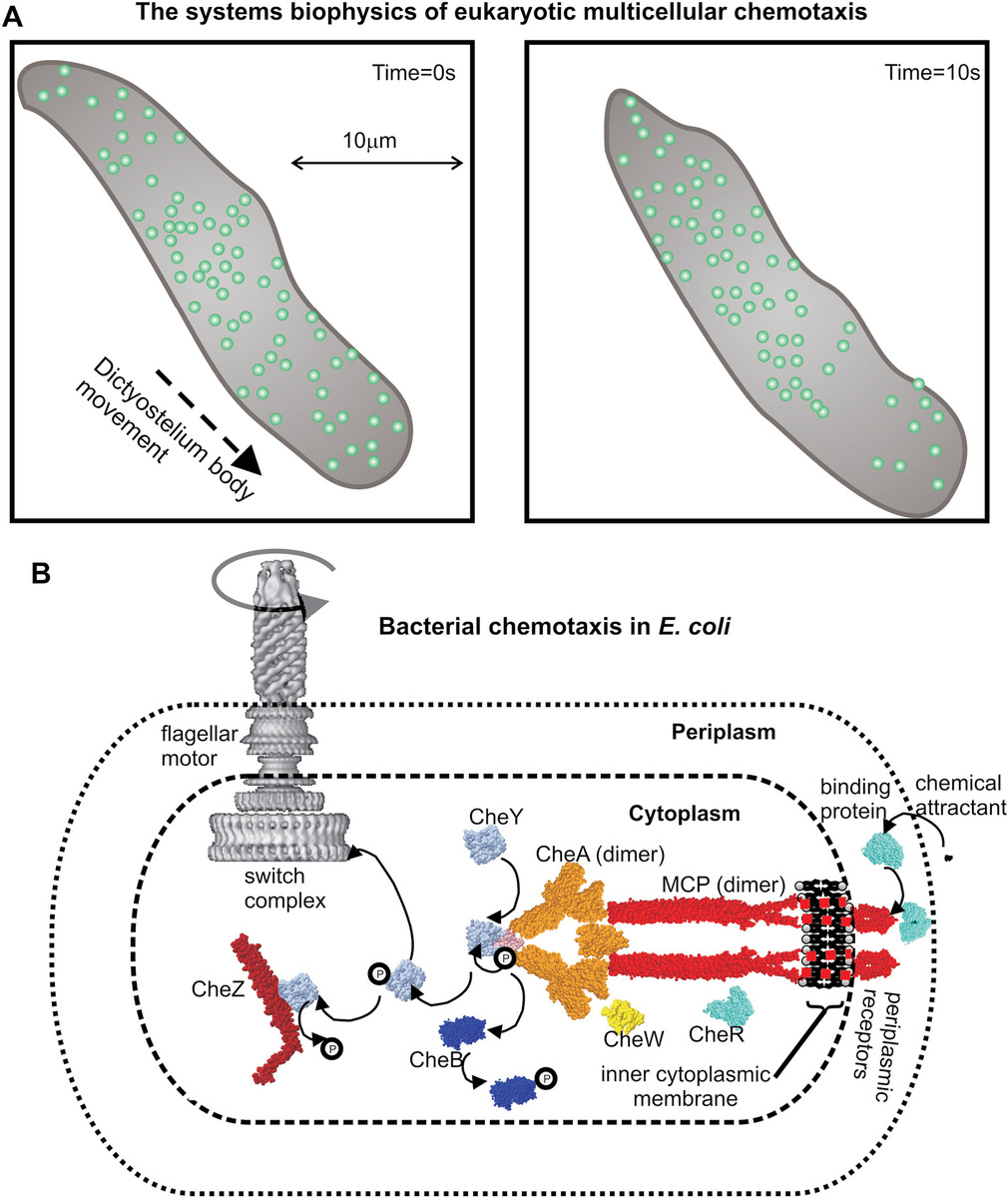
Figure 9.1 Systems biophysics of cell chemotaxis. (a) A multicellular slime mold body of species Dictyostelium discoideum indicating movement of the whole body (gray) in the direction of a chemoattractant gradient, which results in a redistribution of chemoattractant receptor complexes (circles) in the cell membrane after perturbing the chemoattractant concentration gradient (right panel). (b) Schematic indicating the different protein components that comprise the bacterial chemotaxis pathway in Escherichia coli, which results in a change in the rotational state of the flagellar motor in response to detected concentration changes in chemoattractant outside the cell.
In eukaryotic cells, such as in those of the multicellular organism Dictyostelium, the detection of the direction of a concentration gradient of an external chemical is made by a complex mechanism that essentially compares the rate of binding of ligand by receptors on one side to those on the other. That is, it utilizes the physical length scale of the cell to generate probes in different regions of the concentration gradient such that on the side of the higher concentration there will be a small but significant and measurable increase in the rate of ligand binding compared to the opposite side of the cell. This is in effect spatial sampling of the concentration gradient. Prokaryotic cells such as bacteria do not use such a mechanism because their physical length scale of ~10−6 m results in far too small a difference in ligand binding rates either side of the cell above the level of stochastic noise, at least for the relatively small concentration gradients in external ligand that the cell may need to detect. Instead, the cellular strategy evolved is one of temporal sampling of the concentration gradient.
Bacterial sensing and reaction to their environment has been well studied using biophysical tools, in particular fluorescence microscopy in living, functional cells at a single-molecule level. Their ability to swim up a concentration gradient of a chemical attractant is well known, so these cells can clearly detect their surroundings and act appropriately. These systems are excellent models for general sensory networks in far more complex organisms—one of the great advantages of using bacteria is that their comparative low complexity allows experiments to be far more controlled and their results far more definitive in terms of elucidating characteristics of the key molecular components in their original biological context (see Chapter 7).
The range of signals detected by bacteria is enormous, including not only nutrients but also local oxygen concentration and the presence of toxins and fluctuations in pressure in the immediate surroundings, but the means by which signals are detected and relayed have strong generic features throughout. For similar reasons in studying single bacteria, we can increase our understanding of sensory networks in far more complicated multicellular creatures. But a key feature of bacterial chemotaxis is that different proteins in the pathway can be monitored using fluorescent protein labeling strategies (see Chapter 7) coupled with advanced single-molecule localization microscopy techniques (see Chapter 4) to monitor the spatial distribution of each component in real time as a function of perturbation in the external chemoattractant concentration, which enables systems biophysics models of the whole-cell level process of bacterial chemotaxis to be developed.
9.2.2 Molecular Networks
Many complex systems, both biological and nonbiological, can be represented as networks, and these share several common features. Here, the components of the system feature as nodes, while the interactions between the components are manifested as edges that link nodes. There also exist motifs in networks, which are commonly occurring subdomain patterns found across many different networks, for example, including feedback loops. Modularity is therefore also common to these motifs, in that a network can be seen to be composed of different modular units of motifs. Also, many networks in biology tend to be scale-free networks. This means that their degree of distribution follows a power law such that the fraction P(k) of nodes in the network having k connections to other nodes satisfies
(9.1)where
- γ is usually in the range ~2–3
- A is a normalization constant ensuring that the sum of all P values is exactly 1
Molecular networks allow regulation of processes at the cost of some redundancy in the system, but also impart robustness to noise. The most detailed type of molecular network involves metabolic reactions, since these involve not only reactions, substrates, and products, but also enzymes that catalyze the reactions.
The Barabási–Albert model is an algorithm for generating random scale-free networks. It operates by generating new edges at each node in an initial system by a method of probabilistic attachment. It is valuable here in the context of creating a synthetic, controlled network that has scale-free properties but which is a more reduced version of real, complex biological network. Thus, it can be used to develop general analytical methods for investigating scale-free network properties. Of key importance here is the robust identification of genuine nodes in a real network. There are several node clustering algorithms available, for example, the k-means algorithm alluded to briefly previously in the context of identifying different Förster resonance energy transfer (FRET) states in fluorescence microscopy (see Chapter 4) and to clustering of images of the same subclass in principal component analysis (PCA) (see Chapter 8).
The general k-means clustering algorithm functions to output k mean clusters from a data set of n points, such that k < n. It is structured as follows:
- Initialize by randomly generating k initial clusters, each with k associated mean values, from the data set where k is usually relatively small compared to n.
- k clusters are created by associating each data point with the nearest mean from a cluster. This can often be represented visually using partitions between the data points on a Voronoi diagram. This is mathematically equivalent to assigning each data point to the cluster whose mean value results in the minimum within-cluster sum of squares value.
- After partitioning, the data points then calculate the new centroid value from each of the k clusters.
- Iterate steps 2 and 3 until convergence. At this stage, rejection/acceptance criteria can also be applied on putative clusters (e.g., to insist that to be within a given cluster all distances between data points must be less than a predetermined threshold, if not then remove these points from the putative cluster, which, after several iterations, may result in eroding that cluster entirely).
In biological applications, network theory has been applied to interactions between biomolecules, especially protein–protein interactions and metabolic interactions, including cell signaling and gene regulation in particular, as well as networks that model the organization of cellular components, disease states such as cancer, and species evolution models. Many aspects of systems biology can be explored using network theory.
Bacterial chemotaxis again is an ideal system for aligning systems biology and biophysical experimentation for the study of biomolecular interaction networks. Bacteria live in a dynamic, often harsh environment in which other cells compete for finite food resources. Sensory systems have evolved for highly efficient detection of external chemicals. The manner in which this is achieved is fundamentally different from the general operating principles of many biological systems in that no genetic regulation (see Chapter 7) as such appears to be involved. Signal detection and transduction does not involve any direct change in the amount or type of proteins that are made from the genes, but rather utilizes a network of proteins and protein complexes in situ to bring about this end. In essence, when one views a typical bacterium such as E. coli under the microscope, we see that its swimming consists of smooth runs of perhaps a few seconds mixed with cell tumbling events that last on the order of a few hundred milliseconds (see Chapter 8).
After each tumble, the cell swimming direction is randomized, so in effect each cell performs a 3D random walk. However, the key feature to bacterial chemotaxis is that if a chemical attractant is added to the solution, then the rate of tumbling drops off—the overall effect is that the cell swimming, although still essentially randomized by tumbling, is then biased in the direction of an increasing concentration of the attractant; in other words, this imparts an ability to move closer to a food source. The mechanisms behind this have been studied using optical microscopy on active, living cells, and single-molecule experiments are now starting to offer enormous insight into systems-level behavior.
Much of our experimental knowledge comes from the chemosensory system exhibited by the bacteria E. coli and Salmonella enterica, and it is worth discussing this paradigm system in reasonable depth since it illustrates some remarkable general features of signal transduction regulation that are applicable to several different systems. Figure 9.1b illustrates a cartoon of our understanding to date based on these species in terms of the approximate spatial locations and key interactions of the various molecular components of the complete system. Traveling in the direction of the signal, that is, from the outside of the cell in the first subsystem we encounter concerns the primary detection of chemicals outside the cell. Here, we find many thousands of tightly packed copies of a protein complex, which forms a chemoreceptor spanning the cell membrane (these complexes can undergo chemical modification by methyl groups and are thus described as methyl-accepting chemotaxis proteins [MCPs]).
The MCPs are linked via the protein CheW to the CheA protein. This component has a phosphate group bound to it, which can be shifted to another part of the same molecule. This process is known as transautophosphorylation, and it was found that the extent of this transautophosphorylation is increased in response to a decrease in local chemoattractant binding to the MCPs. Two different proteins known as CheB and CheY compete in binding specifically to this transferred phosphoryl group. Phosphorylated CheB (CheB-P) catalyzes demethylation of the MCPs and controls receptor adaptation in coordination with CheR that catalyzes MCP methylation, which thus serves as a negative feedback system to adapt the chemoreceptors to the size of the external chemical attractant signal, while phosphorylated CheY-P binds to the protein FliM on the rotary motor and causes the direction of rotation to reverse with CheZ being required for signal termination by catalyzing dephosphorylation of CheY-P back to CheY.
Biochemical reactions in molecular interaction networks can be solved computationally using the Gillespie algorithm. The Gillespie algorithm (or the Doob–Gillespie algorithm) generates a statistically optimized solution to a stochastic mathematical equation, for example, to simulate biochemical reactions efficiently. The algorithm is a form of Monte Carlo simulation. For example, consider two biomolecules A and B that reversibly bind to form AB, with forward and reverse rates for the process k1 and k−1. So, the total reaction rate Rtot is given by
(9.2)Here, square brackets indicate concentration values. This simple system here could utilize the Gillespie algorithm as follows:
- Initialize the numbers of A and B in the system, the reaction constants, and random number generator seed.
- Calculate the time to the next reaction by advancing the current time t of the simulation to time t + Δt, where Δt is optimized to be small enough to ensure that the forward and reverse reaction events in that time interval have a small probability of occurring (e.g., ~0.3–0.5, similar to that used in molecular MC simulations, see Chapter 8).
- Calculate the forward and reverse reaction event deterministic probability values, p1 and p−1, respectively, as
(9.3)
- Compare these probabilities against pseudorandom numbers generated in the range 0–1 to decide if the reaction event has occurred or not.
- Update the system with new values of number of A and B, etc., and iterate back to step 2.
This can clearly be generalized to far more complex reactions involving multiple different biomolecule types, provided the rate constants are well defined. There are, as we will see in the following text, several examples of rate constants that are functions of the reactant and product molecule concentrations (this implies that there is feedback in the system) in a nontrivial way. This adds to the computational complexity of the simulation, but these more complex schemes can still be incorporated into a modified Gillespie algorithm. What is not embodied in this approach however is any spatial information, since the assumption is clearly one of a reaction-limited regime (see Chapter 8).
9.3 Synthetic Biology, Biomimicry, and Bionanotechnology
Richard Feynman, one of the forefathers of the theory of quantum electrodynamics in theoretical physics, a genius, and a notorious bongo-drum enthusiast, is also viewed by many as the prophet who heralded a future era of synthetic biology and bionanotechnology. For example, he stated something that one might consider to be the entry point into the general engineering of materials, in one sentence that he thought in the English language conveyed the most information in the fewest words:
All things are made of atoms.
So, by implication, it’s just a matter of rearranging them to make something else. Feynman also left the world in 1988 with a quote written on his university blackboard in Caltech, stating
What I cannot create, I do not understand.
It is tempting to suggest, which others have done, that Feynman had synthetic engineering approaches in mind when he wrote this, though the sentence he wrote following this, which was
Know how to solve every problem that has been solved
suggests rather that his own thoughts were toward “creating” mathematical solutions on pencil and paper, as opposed to creating novel, nonnatural materials. However, Feynman did give a lecture in 1959 titled “There’s Plenty of Room at the Bottom,” which suggests at least that he was very much aware of a new era of studying matter at the very small length scale in biological systems:
A biological system can be exceedingly small. Many of the cells are very tiny, but they are very active; they manufacture various substances; they walk around; they wiggle; and they do all kinds of marvelous things—all on a very small scale.
Feynman is perhaps not the grand inventor of synthetic biology, bioengineering, and nanotechnology, indeed the latter phrase was first coined later by the Japanese researcher Taniguchi (1974). However, he was the first physical scientist to clearly emphasize the machine-like nature of the way that biology operates, which is key to synthetic biology approaches.
Synthetic biology can be broadly defined as the study and engineering of synthetic devices for “useful purposes,” which have been inspired by natural biological machines and processes. It often employs many similar biophysical tools and techniques of modern systems biology, but the key difference is that synthetic biology is really an engineering science, that is, it is about making something.
There is also a subtle and fascinating philosophical argument though that suggests that in many ways synthetic biology approaches can advance our knowledge of the life sciences in a more pragmatic and transparent way than more conventional hypothesis-driven investigations. In essence, the theory goes, humans are great at identifying putative patterns in data, and these patterns can then be packaged into a model, which is ultimately an approximation to explain these data using sound physical science principles. However, the model may be wrong, and scientists can spend much of their professional careers in trying to get it right. Whereas engineering approaches, as in synthetic biology, set a challenge for something to be made, as opposed to testing a model as such.
An example is the challenge of how to send someone to the moon, and back again. There are lots of technical problems encountered on the way, but once the ultimate challenge set has been successfully confronted, then whatever science went into tackling the challenge must contain key elements of the correct model. In other words, engineering challenges can often cut to the chase and result in a far more robust understanding of the underlying science compared to methods that explore different hypotheses within component models.
Synthetic biology can operate both from a top-down or bottom-up context, for example, by stripping away components from an existing biological system to reduce it to more basic components, as exemplified by the artificial cells developed by Craig Venter (see Chapter 2). These top-down approaches can also be viewed as a redesign of natural biology or reverse engineering—adapting nature, making it more efficient for the specific set of tasks that you wish the new design to perform. Similarly, a device can be generated into larger systems by combining smaller length scale components that have been inspired by existing components in the natural world, but now in an artificial combination not seen in nature. Thus, creating a totally new artificial device, but inspired by biology, for example, in the use of oil-stabilized nanodroplets that utilize soft-matter nanopores in their outer membranes that can be joined together to create a complex array with a far greater complexity of function than a single droplet (see Chapter 6).
Although such synthetic biology devices can span multiple length scales, much current research is focused at the nanometer length scale. The motivation comes from the glacial time scales of evolution resulting in a myriad of optimized natural technological solutions to a range of challenging environmental problems. Life has existed on planet Earth for around 4 billion years in which time the process of genetic mutation combined with selective environmental pressures has resulted in highly optimized evolutionary solutions to biological problems at the molecular level. These are examples of established bionanotechnology. Thus, instead of attempting to design miniaturized devices completely de novo, it makes sense to try to learn lessons from the natural world, concerning the physical architecture of natural molecular machines and subcellular structures, and the processing structures of cellular functions, that have evolved to perform optimized biological roles.
The range of biophysics tools relevant to synthetic biology is large. These include in particular many fluorescence-based imaging detection methods and electrical measurements and control tools. Several synthetic biology methods utilize surface-based approaches, and so many surface chemistry biophysics tools are valuable. Similarly, biophysics tools that measure molecular interactions are useful in characterizing the performance of devices. Also, atomic force microscopy (AFM) has relevance here, both for imaging characterization of synthetic constructs on surfaces and also for smart positioning of specific synthetic constructs to different regions of a surface (see Chapter 6). Many of these devices have potential benefits to healthcare, and these are discussed in a separate section later in this chapter.
The general area of study of biological processes and structures with a view to generating newly inspired designs and technologies is called biomicry. Structural coloration, as exhibited in the well-known iridescence of the wings of many species of butterfly, is an excellent example but is also found in myriad species including the feathers of several birds, insect wing cases such as many beetles, bees, dragonflies, moths. It is also observed in fish scales, plant leaves and fruit, and the shells of several mollusks.
Many examples of this phenomenon arise from single or multilayer thin film interference and scattering effects. To understand the basic principle, some of the incident light of wavelength λ propagated in a medium of refraction index n0 will be reflected from the surface of a thin film at angle θ0, while a proportion will be refracted through the film of thickness d1 and refractive index n1 at an angle θ1, some of which will then reflect from the opposite boundary back through the film and into the original medium. Back-reflected light will then emerge if the conditions for constructive interference are met between all the multiple reflected beams. For this single thin film system, the condition for constructive interference is given by 2n1d1cosθ1=(m – 1/2)λ where m is a positive integer.
This process can occur for an arbitrary number of layers of different thicknesses and refractive indices (Kinosita et al., 2008), and since the conditions for constructive interference are dependent on the wavelength of incident light these multilayers can be used to generate precisely tuned spectral characteristics of emergent light from a broad spectrum incident light source such as sunlight; for example, the beetle Chrysina resplendens contains ~120 thin layers which produce a bright iridescent gold color (see Worked Case Example 9.3). Structural coloration has an attraction compared to conventional pigment-based coloration technologies in having high brightness which does not fade, plus having iridescence and polarization effects, and a far broader spectral diversity which pigment-based systems cannot achieve including color tuneability.
There are myriad other examples of biomimicry which have emerged over the past decade, methods of developing highly advanced structured light (which refers to the engineering of optical fields both spatially and temporally in all of their degrees of freedom) from biological photonics crystal structures, smart syringes which cause significantly less pain by adapting structures inspired from the mouth parts of mosquitos, synthetic proteins motivated by silk produced from spiders and silk worms designed to help wound healing, natural photosynthetic machinery being adapted to develop devices to reduce global warming by capturing carbon from the atmosphere, and even faster trains conceived by using the core fluid dynamics concepts derived from the shape of the beak of the kingfisher bird (for a super and fun suite of more examples from the animal kingdom at least, check out the inspired podcasts by Patrick Aryee, 2021-22).
9.3.1 Common Principles: Templates, Modularity, Hierarchy, and Self-Assembly
There are four key principles that are largely common to synthetic biology: the use of scaffolds or templates, modularity of components of devices (and of the subunits that comprise the components), the hierarchical length scales of components used, and the process of self-assembly. Nature uses templates or scaffolds that direct the fabrication of biological structures. For example, DNA replication uses a scaffold of an existing DNA strand to make another one.
Synthetic biology components are implicitly modular in nature. Components can be transposed from one context to another, for example, to generate a modified device from different modules. A key feature here is one of interchangeable parts. Namely, that different modules, or parts of modules, can be interchanged to generate a different output or function.
This sort of snap-fit modularity implies a natural hierarchy of length scales, such that the complexity of the device scales with the number of modules used and thus with the effective length scale of the system, though this scaling is often far from linear and more likely to be exponential in nature. This hierarchical effect is not to say that these are simply materials out of which larger objects can be built, but rather that they are complete and complex systems. Modularity also features commonly at the level of molecular machines, which often comprise parts of synthetic biology devices. For example, molecular machines often contain specific protein subunits in multiple copies.
Self-assembly is perhaps the most important feature of synthetic biology. A key advantage with synthetic biology components is that many of them will assemble spontaneously from solution. For example, even a ribosome or a virus, which are examples of very complex established bionanotechnologies, can assemble correctly in solution if all key components are present in roughly the correct relative stoichiometries.
9.3.2 Synthesizing Biological Circuits
Many molecular regulation systems (e.g., see Chapter 7) can be treated as a distinct biological circuit. Some, as exemplified by bacterial chemotaxis, are pure protein circuits. A circuit level description of bacterial chemotaxis relevant to E. coli bacteria is given in Figure 9.2a. However, the majority of natural biological circuits involve ultimately gene regulation and are described as gene circuits. In other words, a genetic module has inputs (transcription factors [TFs]) and outputs (expressed proteins or peptides), and many of which can function autonomously in the sense of performing these functions when inserted at different loci in the genome. Several artificial genetic systems have now been developed, some of which have clear diagnostic potential for understanding and potentially treating human diseases. These are engineered cellular regulatory circuits in the genomes of living organisms, designed in much the same way as engineers fabricate microscale electronics technology. Examples include oscillators (e.g., periodic fluctuations in time of the protein output of an expressed gene), pulse generators, latches, and time-delayed responses.
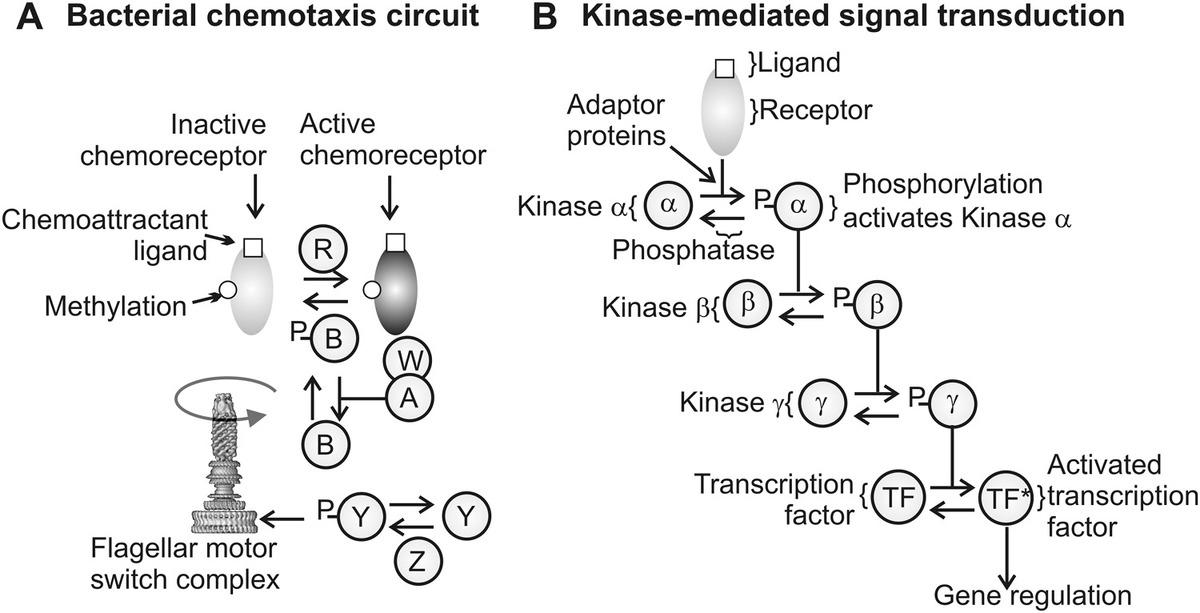
Figure 9.2 Biological circuits. (a) Equivalent protein circuit for bacterial chemotaxis, A, B, W, Y, and Z are chemotaxis proteins CheA, CheB, CheW, CheY, and CheZ, respectively, with P indicating phosphorylation. (b) A common method of cellular signal transduction following detection of a ligand by a receptor, typically in the cell membrane, involves a cascade of serial phosphorylation steps of tyrosine kinase enzymes (depicted here by example with some genetic kinases α, β, and γ), which ultimately activates a transcription factor, which in turn can then result in regulation of a specific gene or set of genes.
One of the simplest biological circuits is that found in many gene expression systems in which the protein product from the gene expression activates further expression from the promoter of the gene in question. In this simple case, the concentration C of an expressed protein can be modeled by the following rate equation:
(9.4)where
- k is the effective activation rate
- R is the concentration of repressor complexes (e.g., a relevant TF)
- p is the probability per unit time that a given promoter of a gene is occupied
The value of p can be modeled as being proportional to a Boltzmann factor exp(−ΔGp/kBT) where Gp is the free energy change involved in binding a repressor molecule to the promoter of the gene. The solution to this rate equation is essentially a sigmoidal response in terms of rate of expression versus levels of expressed protein. In other words, the output expression rate switches from low to high over a small range of protein levels, thus acting in effect as a binary switch, which is controlled by the concentration of that particular protein in the cell (see Worked Case Example 9.1).
Ultimately, natural biological circuits have two core features in common. First, they are optimized to maximize robustness. By this, we mean that the output of a biological circuit is relatively insensitive to changes in biochemical parameters from cell to cell in a population. In order to ensure this, gene circuits also share the feature of involving feedback, that is, some communication between the level of output response and the level of input signal equating in effect to a gain function of the circuit, which depends on the output. Artificial biological circuits need to follow these same core design principles. Many of the components of biological circuits can be monitored and characterized using a wide range of biophysical techniques already discussed previously in this book.
For example, several natural signal transduction pathways have key components that can be adapted to be used for general synthetic biology biosensing. Many of these involve receptor tyrosine kinases. These are structural motifs that contain the amino acid tyrosine, and when a ligand binds to the receptors this induces a conformational change that stimulates autophosphorylation of the receptor (i.e., the receptor acts as an enzyme that catalyzes the binding of phosphate groups to itself). These in turn dock with a specific adapter protein and in doing so activate signaling pathways that generate specific cellular responses depending on the adapter protein. A schematic of this process is depicted in Figure 9.2b.
The point here is that the gene circuit for this response is generic, in that all that needs to be changed to turn it into a detector for another type of biomolecule are the specifics of the receptor complex and the adapter protein used, which thus offers the potential for detecting a range of different biomolecule outside cells and bringing about different, nonnative responses of the host cell. Different combinations can potentially lead to cell survival and proliferation, whereas others might lead to, for example, promoting apoptosis, or programmed cell death (see Chapter 2), which could thus have potential in destroying diseased cells in a controllable way (also, see the section in this chapter on personalizing healthcare). Similarly, the output can be tailored to express a TF that stimulates the production of a particular structural protein. For example, yeast cells have been used as a model organism to design such a system using an actin regulatory switch known as N-WASP to controllably manufacture F-actin filaments.
Many gene circuits also have logic gate features to them. For example, it is possible to engineer an AND gate using systems that require activation from two inputs to generate an output response. This is exemplified in the Y2H assay discussed previously (see Chapter 7), and there are similar gene circuit examples of OR and NOT gates. This is particularly valuable since it in principle then allows the generic design principles of electrical logic circuitry to be aligned directly with these biological circuits.
One issue with gene circuit design is the approximations used in modeling their response. For example, spatial effects are usually ignored in characterizing the behavior of gene circuits. This assumes that biochemical reactions in the system occur on time scales much slower than the typical diffusional time required for mixing of the reactants or, in other words, a reaction-limited regime (see Chapter 8). Also, stochastic effects are often ignored, that is, instead of modeling the input and output of a gene circuit as a series of discrete events, an approximation is made to represent both as continuous rather than discrete parameters. Often, in larger scale gene circuit networks, such approximations are required to generate computationally tractable simulations. However, these assumptions can often be flawed in real, extensive gene circuit networks, resulting in emergent behaviors that are sometimes difficult to predict. However, relatively simple kinetics analysis applied to gene circuits can often provide useful insight into the general output functions of a genetic module (see Worked Case Example 9.1).
In practice, there are also more fundamental biological causes for design problems of gene circuits. For example, there are sometimes cooperative effects that can occur between different gene circuits that are not embodied in a simple Boolean logic design model. One of these cooperative effects is mechanical in origin. For example, there is good evidence that mechanical perturbations in DNA can be propagated over thousands of nucleotide base pairs to change the state of a specific gene’s expression, that is, to turn it “on” or “off.” These effects can be measured using, for example, single-molecule force manipulation techniques such as magnetic tweezers (see Chapter 6), and there is increasing evidence that mechanical propagation is limited to the so-called topological domains in DNA, so that certain protein complexes bound to the DNA act as buffers to prevent propagation of phonons across them into adjacent domains. This is important since it implies that a simple snap-fit process may not work but requires thought as to where specifically gene circuits are engineered in a genome relative to other gene circuits.
Another biological challenge to the design of artificial gene circuits is epigenetics. Epigenetic changes to the expression of genes occur in all organisms. These are heritable changes, primarily by changes to the state of chemical methylation of the DNA, which propagate to subsequent generations without a change of the actual nucleotide sequence in the DNA (see Chapter 2). The effect of such epigenetic modifications is often different to predict from base principles, especially for an extensive network of coupled gene circuits, resulting in nontrivial design issues.
9.3.3 DNA Origami
DNA origami is a nanotechnology that utilizes the specific nucleotide base pairing of the DNA double helix to generate novel DNA nanostructures. This DNA nanotechnology was first hypothesized by Nadrian “Ned” Seeman in the 1980s (Seeman, 1982), though it was two decades later that the true potential of this speculation was first empirically confirmed using a range of biophysics tools among others. Double-stranded DNA has a persistence length of ~50 nm (see Chapter 8), implying that over a length scale of ~0–50 nm, it is in effect a stiff rod. Also, DNA has base pairing that is specific to the nucleotide types (C base pairs with G, A with T, see Chapter 2). These two factors make DNA an ideal construction material for structures at or around the nanometer length scale, in that, provided the length of each “rod” is less than ~50 nm, complex structures can be assembled on the basis of their nucleotide sequence. Since its inception toward the end of the twentieth century, these physical properties of DNA have been exploited in DNA origami to create a wide range of different DNA nanostructures. Biophysics tools that have been used to characterize such complex DNA nanostructure structures include fluorescence microscopy, AFM, and electron microscopy (EM) imaging, though the workhorse technique for all of this work is gel electrophoresis, which can at least confirm relatively quickly if key stages in the nanostructure assembly process have worked or not.
DNA origami offers the potential to use artificial DNA nucleotide sequences designed with the specific intention for creating novel synthetic nanoscale structures that may have useful applications (see Turberfield, 2011). It has emerged into a promising area of research both in applying single-molecule biophysics tools in characterizing DNA nanostructures, and in also utilizing the structures for further single-molecule biophysics investigations. An advantage with such structures is that, in general, they self-assemble spontaneously with high efficiency from solutions containing the correct relative stoichiometry of strand components at the correct pH and ionic strength, following controlled heating of the solution to denature or “melt” the existing double strands to single strands, and then controlled cooling allowing stable structures to self-assemble in a process called thermal annealing. Usually, sequences are designed to minimize undesirable base pairing, which can generate a range of different suboptimal structures.
In their simplest forms, DNA nanostructures include 2D array (Figure 9.3a). For example, four DNA strands, whose nucleotide sequences are designed to be permutationally complementary (e.g., strand 1 is complementary to strand 2 and 3, strand 2 is complementary to strand 3 and 4) can self-assemble into a stable square lattice 2D array, and similarly a three-strand combination can give rise to a hexagonal 2D array (Figure 9.3a). By using more complex complementary strand combinations, basic geometrical 3D nanostructures can be generated, such as cubes, octahedra, and tetrahedra (Figure 9.3b), as well as more complex geometries exemplified by dodecahedra and icosahedra. Typically, a range of multimers are formed in the first instance, but these can be separated into monomer nanostructure units by using repeated enzymatic treatment with specific restriction nuclease enzymes to controllably break apart the multimers (see Chapter 7).
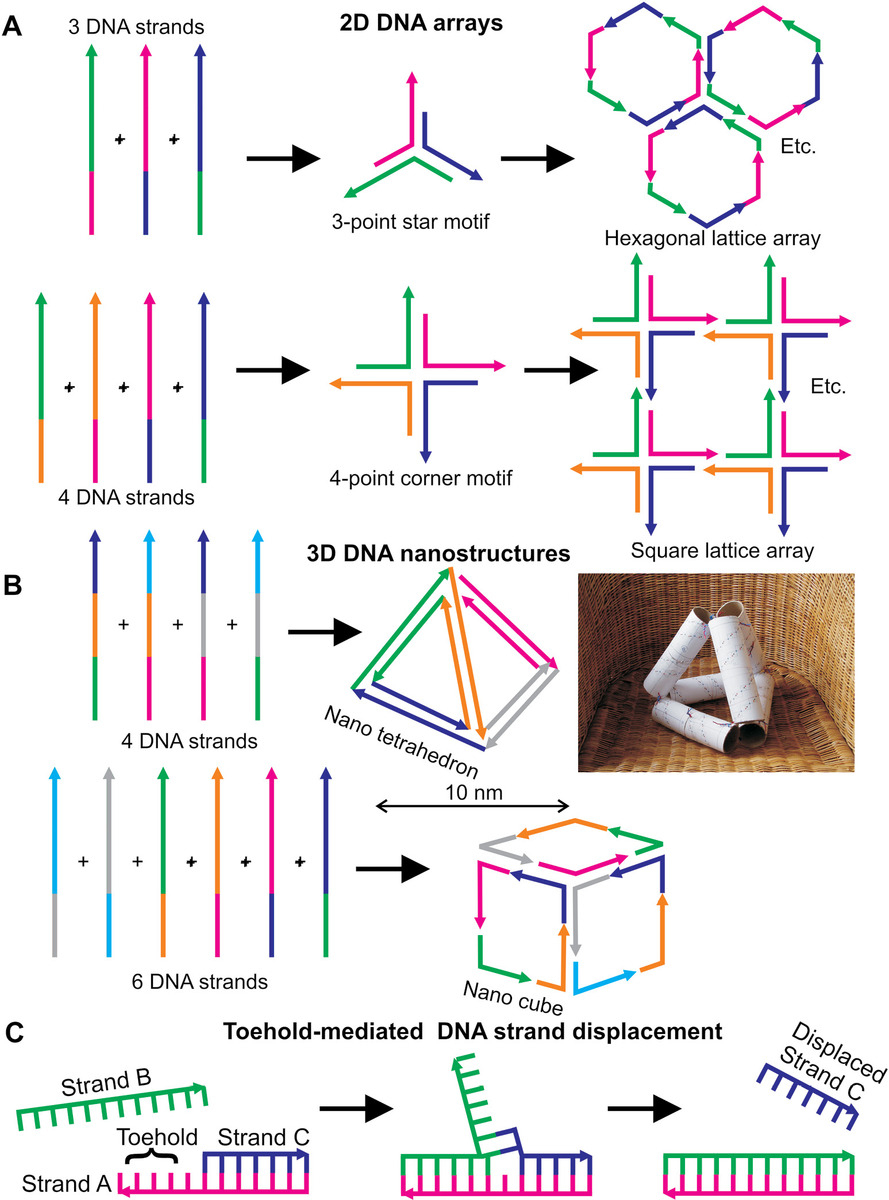
Figure 9.3 DNA origami. (a) Three or four strands of DNA can be designed to have complementary segments as indicated, giving rise to self-assembled 2D arrays with either hexagonal or square lattices, respectively. (b) Using more complex design involving more complementary DNA segments, 3D DNA nanostructures can be generated, such as tetrahedrons and cubes shown here (though more generally nontrivial geometrical shapes objects can also be generated). The original DNA tetrahedron design was conceived using six toilet roll tubes, some paper, and some colored bits of bendy wire (right panel: Courtesy of Richard Berry, University of Oxford, Oxford, UK). (c) Artificial DNA molecular motors all use toehold-mediated strand displacement, for example, strands A and B here are complementary, and so the addition of strand B to the solution will displace strand C from the A–C DNA nanostructure indicated.
For example (see Goodman et al., 2005), a tetrahedron can be made from four 55 nucleotide base DNA strands. Each of the six edges of the tetrahedron is composed of one of six 17-base “edge subsequences” (edge length ~7 nm), which is hybridized to its complementary segment. Each DNA strand contains three of these subsequences, or their complements, which are separated by short sequences specifically designed not to hybridize with a complementary strand, and thus act as a “hinge,” to ensure that the tetrahedron vertices have flexibility to accommodate a 60° kink. Each strand runs around one of the four faces and is hybridized to the three strands running around the neighboring faces at the shared edges, and each vertex is a nicked three-arm junction, and can exist as two stereoisomers (see Chapter 2). Such a structure has the potential for acting as nanoscale brick for more extensive synthetic 3D structures.
A valuable lesson to learn for the student is the importance of basic, rudimentary thought, when it comes to the intellectual process of designing such nanostructures. When published in research articles in their final form, fancy graphics are inevitably employed. However, the initial intellectual process is often far more basic, down-to-earth, and human than this, as can be seen wonderfully exemplified from the right panel of Figure 9.3b.
It is also possible to engineer larger DNA nanostructures than the simple 3D geometrical shapes. These can include structures that are more complex than simple geometrical objects. In principle, a single strand of DNA can be used to generate such structures, referred to as the scaffold, though to hold it stably in place often requires several short sequences known as staples, which pin down certain duplex regions relative to each other, which might be liable to move relative to each other significantly otherwise. Such exotic structures have included 2D tiles, star shapes and 2D snowflake images, smiley faces, and embossed nanolettering, even a rough nanoscale map of North and South America. Many of these exotic designs, and the engineering principles used in their formulations, can be seen in the work of Caltech’s Paul Rothemund in a pioneering research paper that was cited roughly 3000 times in the first 10 years since its publication, which says a great deal about the huge impact it has had to this emerging field (Rothemund, 2006).
One limit to the size of an artificial DNA structure is mismatched defects. For example, base pair interactions that do not rely on simple Watson–Crick base pairing. Although relatively uncommon, the effects over larger sections of DNA structures may be cumulative. Also, the purification methods are currently relatively low throughput, which arguably has limited extensive commercial exploitation for “useful” structures beyond the satisfaction of designing nanoscale smiley faces, though it seems tempting to imagine that these technological barriers will be reduced by future progress.
“Useful” DNA nanostructures include nanostructures that can be used as calibration tools or standards for advanced fluorescence microscopy techniques. For example, since optimized DNA nanostructures have well-defined atomic coordinates, then different color dyes can be attached as very specific locations and used as a calibration sample in FRET measurements (see Chapter 4).
Also, DNA origami can generate valuable 2D arrays that can be used as templates for the attachment of proteins. This has enormous potential for generating atomic level structural detail of membrane proteins and complexes. As discussed previously (see Chapter 7), there are technical challenges of generating stable lipid–protein interactions in a large putative crystal structure from membrane proteins, making it difficult to probe structures using x-ray crystallography. The primary alternative technique of nuclear magnetic resonance (NMR) (see Chapter 5) has associated disadvantages also. For example, it requires purified samples >95% purity in the concentration of several mg mL−1 typically prepared from recombinant protein to be prepared by time-consuming genetic modification of bacteria such as E. coli (see Chapter 7). NMR is also relatively insensitive for small proteins whose molecular weight is smaller than ~50 kDa.
The main alternative structural determination technique for membrane proteins is electron cryo-EM that allows direct imaging of biomolecules from a rapidly frozen solution supported on an electron-transparent carbon film and circumvents many of the problems associated with NMR and x-ray crystallography (see Chapter 5). However, high electron current flux in EM imaging can damage samples. Also, there are increased risks of protein sample aggregation at the high concentrations typically used, and the random orientation of particles means that analysis is limited to small groups at a time with limited potential for high-throughput analysis, though PCA has to somewhat tackled many of these issues (see Chapter 8). If instead one attaches the target protein to specifically engineered binding sites on a self-assembled 2D DNA template, this minimizes many of these issues. It also opens the possibility for 2D crystallography if proteins can be bound to the template in consistent orientations, for example, using multiple binding sites.
DNA origami can also be utilized to make dynamic as opposed to just static nanostructures can be made from DNA. These are examples of artificial molecular motors. A motivation to develop artificial molecular motors is for the transporting of specific biomedical cargo molecules for use in lab-on-a-chip devices (see later text). Several such devices have been constructed from DNA, inspired by the mechanisms of natural molecular motors (see Chapter 8). The key process in all DNA-based artificial molecular motors is known as toehold-mediated strand displacement (Figure 9.3c). Here, a single-stranded DNA toehold (also known as an overhang or sticky end) is created at the end of a double-stranded (i.e., duplex) segment of DNA called a “toehold.” This single-stranded toehold can bind to an invading DNA strand that competes with the bound strand. Since unpaired bases have a higher effective Gibbs free energy than paired bases, then the system reaches steady state when the minimum number of unpaired bases is reached, which results in displacement of the originally bound strand. This strand displacement imparts a force on the remaining duplex structure, thus equivalent to the power stroke of natural molecular machines (see Chapter 8), with the equivalent “fuel” being the invading DNA strand. Such developments currently show promise at the point of writing this book. However, issues include artificial motors being slow and inefficient compared to native molecular motors, and DNA logic circuits are not currently as reliable as conventional electronic ones.
One interesting further application of DNA origami lies in computationally complicated optimization–minimization problems. These are exemplified by the so-called traveling salesman problem:
Given a finite number of cities and the distances between them what is the shortest route to take such that each city is visited just once prior to returning to the starting city?
This turns out to be precisely the same problem as a single strand of DNA exploring the most optimal annealing routes for a self-assembly duplex formation process. Thus, biophysical observations of the kinetics of annealing can potentially be used as a biomolecular computational metric to complex optimization–minimization problems.
9.3.4 Biofuels, Bioplastics, and a Greener Environment
Synthetic biology approaches have been used to engineer modified cells to generate “green” biofuels, to manufacture biodegradable plastics, and even to clean our environment (a process known as bioremediation). Advanced biofuels may end up being crucial to building a cleaner energy economy. With depletion of fossil fuels and decommissioning of many nuclear power stations coupled with safety and environmental concerns of those remaining, biofuel development has an appeal.
Although at an early stage of development, there are emerging signs of promising progress. For example, certain nanoparticles can increase the efficiency of biofuel production, which employ enzyme catalysis to convert cellulose from plants into smaller sugars high in their fuel value. There are also developments in biobatteries. These are miniaturized electrical charge storage devices that utilize biological materials. Examples are oil-stabilized nanodroplet arrays, discussed previously (see Chapter 6), though currently are low power and inefficient.
Other interesting designs include nanowire microelectrodes that can be energized by a fuel of only a few molecules of natural redox enzymes (Pan et al., 2008). A key challenge here is that for conventional electrical conductors, the electrical resistance varies inversely with the cross-sectional area, so that a material that obeys Ohm’s law of electrical resistance in this way could have significantly very high electrical resistances for wires whose width is of the nanometer length scale, resulting in a highly inefficient generation of heat. Nonbiophysical methods for tackling this issue include the use of superconductive materials whose electrical resistance can be made exceptionally low. Currently, these are limited in their use at relatively low temperatures (e.g., liquid nitrogen); however, it is likely that viable room-temperature superconductive material will be available in the near future.
Biophysics-inspired research into this area has included fabricating nanowires from single DNA molecule templates that are spatially periodically labeled with alternating electron-donor and electron-acceptor probes. These enable electrical conduction through a series of quantum tunneling processes, rather than by conventional electron drift. Similarly, using molecular photonics wires that use a DNA molecule containing multiple FRET acceptor–donor pairs along its length enables the transfer of optical information through space via FRET, thus acting as an optical switch at the nanometer length scale (Heilemann et al., 2004).
In 2012, the estimated average total power consumption of the human world was ~18 TW (1 TW = 1 terawatt = 1012 W), equivalent to the output of almost 10,000 Hoover Dams. The total power production estimated from global photosynthesis is more like 2000 TW, which may indicate a sensible strategy forward to develop methods to harness the energy transduction properties of natural photosynthetic systems. However, the total power available to the Earth from the sun is ~200 PW (1 PW = 1 petawatt = 1015 W)—in this sense, natural photosynthesis is arguably relatively inefficient at only extracting ~1% of the available solar energy. Solar energy that is not reflected/scattered away from plant leaves is mainly transformed to heat as opposed to being locked in high-energy chemical bonds in molecules of sugars.
One route being developed to harness this process more controllably is in the modification of natural cyanobacteria (photosynthetic bacteria), potentially to develop synthetic chloroplasts by introducing them into other more complex organisms. These cyanobacteria contain carboxysomes, which have a protein shell similar in size and shape to the capsid coat of viruses but contain the enzyme RuBisCo that catalyzes photosynthesis. The application of these carboxysomes to different organisms has not yet been clearly demonstrated, but chloroplasts have been imported into foreign mammalian macrophage cells and zebrafish embryos, to increase their photosynthetic yield (Agapakis et al., 2011).
Modification of bacteria has also been applied in the development of synthetic strains, which can generate alcohols as fuels, for example, butanol. This method manipulates the natural fermentation process by adapting the acetyl-CoA complex that forms an essential hub between many metabolic pathways, most importantly in the Krebs cycle (see Chapter 2). The key challenge is that the alcohol is toxic to the cell, so achieving commercially feasible concentrations is difficult. However, biophysics tools such as fluorescence microscopy and mass spectrometry can be used to assist in understanding how the molecular homeostasis of the acetyl-CoA is achieved and potentially can be manipulated.
9.3.5 Engineering Artificial Peptides, Proteins, and Larger Protein Complexes
Bioengineering of peptides and proteins can take multiple forms. One is the genetic manipulation/modification of existing native proteins starting from their composition of natural amino acids. Another is the chemical conjugation of native proteins (see Chapter 7), which in part crosses over into genetic modification. And finally one can also utilize unnatural amino acids in peptide and protein synthesis to generate truly artificial products.
Engineering of proteins using genetic modifications typically involves point mutations of single amino acids to modify their function. Often, the effect is to impair functionality, for example, to impair a kinase enzyme from its normal ability to catalyze phosphorylation, but more rarely to increase functionality in some way. The techniques involved are those of standard molecular cloning (Chapter 7). Similarly, genetic modifications can include encoding tags next to genes at the level of the DNA sequence, for example, fluorescent proteins.
Modified proteins have been used in genuine bottom-up synthetic assays to build devices that utilize protein pattern formation. For example, the bacterial proteins MinC, MinD, and MinE, which are responsible for correctly determining the position of cell division in growing E. coli bacterial cells (see Chapter 8), have been reconstituted in an artificial noncellular system involving just microwells of different sizes and shapes. These systems require an energy input, provided by the hydrolysis of ATP, but then result in fascinating pattern formation depending on the size and shape of the microwell boundaries, even in the complete absence of cells. These systems have yet to be exploited for “useful” ends, but show enormous potential at being able to develop controllable patterns in solution from just a few protein components, which could have implications for templating of more complexing synthetic devices.
Similarly, other bacterial cell division proteins such as FtsZ have been artificially reconstituted. FtsZ is responsible for the actual constriction of the cell body during the process of cell division, through the formation of a tightening Z-ring. FtsZ can be reconstituted and fluorescently labeled in artificial liposomes with no cells present and fueled by GTP hydrolysis in this case, which can result in controlled liposome constriction that can be monitored in real time using fluorescence microscopy imaging.
The degron system is also a good example of genetic and protein-based bioengineering. As discussed previously (see Chapter 7), this uses genetic modification to insert degron tags onto specific proteins. By inducing the expression of the sspB adapter protein gene, these tagged proteins can then be controllably degraded in real time inside living bacterial cells. This facilitates the investigation of the biological function of these proteins using a range of biophysical techniques, but also has potential for exploitation in synthetic biology devices.
A range of unnatural amino acids have also been developed, which utilize different substituent groups to optimize their physical and chemical properties catered for specific binding environments, which require a combination of genetic and chemical methods to integrate into artificial protein structures. A subset of these is genetically encoded synthetic fluorescent amino acids, used as reporter molecules. These are artificial amino acids that have a covalently bound fluorescent tag engineered into the substituent group. The method of tagging is not via chemical conjugation but rather the amino acid is genetically coded directly into the DNA that codes for a native protein that is to be modified. This essentially involves modifying one of the nonsense codons that normally do not code for an amino acid (see Chapter 2). Currently, the brightness and efficiency of these fluorescent amino acids is still poor for low-light biophysical applications such as single-molecule fluorescence microscopy studies, as well as there being a limitation of the colors available, but there is certainly scope for future development.
Larger length scale synthetic biology devices also utilize macromolecular protein complexes. For example, the protein capsid of virus particles has been used. One such device has used a thin layer of M13 bacteriophage virus particle to construct a piezoelectric generator that is sufficient to operate a liquid crystal display.
9.3.6 Biomimetic Materials
Metamaterials are materials engineered to have properties that have not yet been found in nature. Biomimetic materials are a subset of metamaterials. They are artificial materials, but they mimic native biological materials and often require several stages of biophysical characterization of their material properties during the bioengineering design and manufacturing processes. Several existing biostructures have been used as inspiration for some of the biomimetic materials.
The development of new photonic material that is biomimetic to natural butterfly wings is a good example. Here, biomimetization of butterfly wings can be performed by a series of metal vapor deposition steps (see Chapter 7). The key step though is actually to use a native wing as a positive mold—this can be first coated in a glass material called chalcogenide to wrap closely around the butterfly structure to a precision of a few nanometers. A procedure called plasma ashing (exposing the sample to a high-energy ion plasma beam) can then be used to destroy the original wing but leaves the glass wrap intact. This can then be further coated using metal vapor deposition as required. The key optical feature of butterfly wings is their ability to function as very efficient photonic bandgap devices, that is, they can select very precisely which regions of the spectrum of light to transit from a broad-spectrum source. This is true not only for visible wavelength, but infrared and ultraviolet also. Biomimetic butterfly wings share these properties but have the added advantage of not being attached to a butterfly.
Another class of biomimetic materials crossover is in the field of biocompatible materials. These are novel, artificial materials used in tissue engineering and regenerative medicine usually to replace native damaged structures in the human body to improve health. As such, we discuss these in this chapter in the section on personalizing healthcare.
9.3.7 Hybrid Bio/Bio–Bio Devices
A number of artificial devices are being fabricated, which incorporate both biological and nonbiological components. For example, it is possible to use the swimming of bacteria to make a 20 μm diameter silicon-based rotor, machined with a submicron precision, and thus an example of genuine nanotechnology, rotate (Hiratsuka et al., 2006). It was the first “engine” that combined living bacteria with nonbiological, inorganic components. The bacterium used was Mycoplasma mobile that normally swims on the surface of soil at a few microns per second. These bacteria follow the curvature of a surface and so will on average follow the curved track around the rotor. By chemically modifying the surface of the bacteria with biotin tags, and then conjugating the rotor surface with streptavidin that has a very strong binding affinity to biotin, the cells stick to the rotor and make it spin around as they swim around its perimeter, at a rotation speed of ~2 Hz that could generate a torque of ~10−15 Nm.
This level of torque is roughly four orders of magnitude smaller than purely inorganic mechanical microscopic motors. However, this should also be contrasted with being five orders of magnitude larger than the torque generated by the power stroke action of the molecular motor myosin on an F-actin filament (see Chapter 8). Microorganisms, such as these bacteria, have had millions of years to evolve ingenious strategies to explore and move around. By harnessing this capability and fusing it with the high-precision technology of silicon at micro- and nanoscale fabrication, one can start to design useful hybrid devices (Figure 9.4).
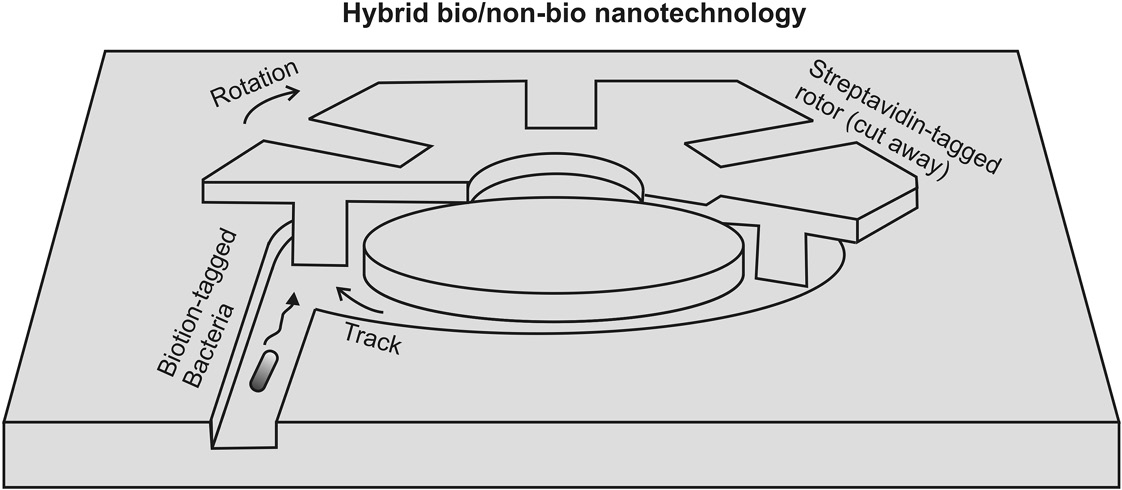
Figure 9.4 Synthetic biology combined with fabricated solid-state micro and nanoscale structures. Cutaway schematic of a hybrid bionanotechnology/non-bionanotechnology device. Here, a 20 μm diameter silicon dioxide rotor is pushed around by the swimming action of the bacterium Mycoplasma mobile, whose surface has been tagged with biotin while that of the rotor has been labeled with streptavidin. The bacterial motion is energized by glucose, and this cell motion is coupled to rotation of the rotor via chemical bonds formed between the biotin and streptavidin.
Another emerging area of hybridizing bio- and nonbiocomponents is bioelectronics. Here, perhaps the most exciting developments involve attempts to design biological transistors.
The transistor was invented in 1947 by physicists John Bardeen, Walter Brattain, and William Shockley, made possible through advances in our understanding of the physics of electron mobility in semiconductor materials. Moore’s law is a heuristic relation, relating time with the size of key integrated circuitry, most especially the transistor, suggesting that technological progress is resulting in a decrease in the size of the transistor by roughly a factor of two every two years. With the enormous developments into shrinking of the effective size of a transistor to less than ~40 nm of the present day, this has increased speed and efficiency in modern computing technology to unprecedented levels, which has affected most areas of biophysical tools.
Interestingly, the size of the modern transistor is now approaching that of assemblages of the larger biological molecular complexes, which drive many of the key processes in biology. Bioengineers have created the first biological transistor from the nucleic acids DNA and RNA, denoted as a transcriptor (Bonnet et al., 2013) in reference to the natural cellular process of transcribing the genetic code embodied in the DNA sequence into molecules of mRNA (see Chapter 2). The transcriptor can be viewed as a biological analog of a solid-state digital transistor in electronic circuitry. For example, transistors control electron flow, whereas transcriptors regulate the flux of RNA polymerase enzymes as they translocate along a DNA molecule whose associated gene is being expressed. Transcriptors use combinations of enzymes called “integrases” that control RNA movement as it is fabricated from the DNA template.
Transistors amplify a relatively small current signal at the base input (or gate in the case of field effect transistors [FETs]) into a much larger current between the emitter/collector (or equivalent voltage between the source/drain in FETs). Similarly, transcriptors respond to small changes in the integrase activity, and these can result in a very large change in the flux of RNA polymerase resulting in significant increases in the level of expression of specific genes. Multiple transcriptors can be cloned on different plasmids and controlled using different chemical induction (see Chapter 7) and then combined in the same way as multiple electronic transistors to generate all the standard logic gates, but inside a living cell. Thus, this presents the opportunity for genuine biocomputation, that is, a biological computer inside a functional cell. An appealing potential application is toward in situ diagnostics and associated therapeutics of human diseases, that is, cells with a capacity to detect the presence of diseases and regulate cellular level interventions as bespoke treatment with no external intervention required (see the section on personalizing healthcare).
9.4 Personalizing Healthcare
Personalized healthcare is a medical model that proposes to cater healthcare specifically to a unique, individual patient, as opposed to relying on generic treatments that are relevant to population-level information. For example, we know that human genomes in general vary significantly from one individual to the next (Chapter 2). Some people have a greater genetic predisposition toward certain disorders and diseases than others. Also, the responses of individual patients to different treatments can vary widely, which potentially affects the outcome of particular medical treatments.
The selection of appropriate, optimal therapies is based on specific information concerning a patient’s genetic, molecular, and cellular makeup. In terms of biophysics, this has involved developments in smart diagnostics such as lab-on-a-chip technologies, and smart, targeted treatment, and cellular delivery methods, including nanomedicine. In addition, computational modeling can be combined with experimental biophysics for more intelligent in silico drug design catered toward specific individuals.
Developing methods to enable personalized healthcare is particularly important regarding the current global increased risks of infection, and the challenges of an increasingly aging population. For infection challenges, the past overuse of antibiotics has led to the emergence of superbugs, such as methicillin or vancomycin resistant Staphylococcus aureus (MRSA and VRSA respectively), which are resistant to many of the traditional antibiotics available. These now impose significant limitations on the successful outcomes of many surgical treatments, cancer therapies and organ transplants; personalized diagnostic biosensing to detect the suite of different infectious pathogens present in different parts of the body in specific individuals could be invaluable in developing catered drug treatments to combat these. For aging issues, the big challenges are heart disease, cancer, and dementia. Again, all these disorders are amenable to personalized biosensing—innovative, fast-response technologies which can utilize appropriate libraries of biomarkers to personalize earlier diagnosis and thereby accelerate a more tailored treatment at far earlier stages in these chronic conditions that has been available previously.
9.4.1 Lab-on-a-Chip and Other New Diagnostic Tools
Developments in microfluidics and surface chemistry conjugation methods (see Chapter 7), photonics, micro- and bioelectronics, and synthetic biology have all facilitated the miniaturization and increased portability of smart biosensing devices. These devices are designed to detect specific features in biological samples, for example, the presence of particular types of cells and/or molecules. In doing so, this presents a diagnostic and high-throughput screening capability reduced to a very small length scale device, hence the phrase lab-on-a-chip. An ultimate aim is to develop systems in which diagnosis can be made by the detection and analysis of microliter quantities of a patient specimen, such as blood, sputum, urine, fed through a miniaturized biomolecular detection device coupled to smart microelectronics.
Typically, these devices consist of hybrid nonbiological solid-state silicon-based substrates with synthetic arrangements of biological matter, in a complex microchip arrangement that often employs controlled microfluidics to convey biological sample material in aqueous solution to one or more detection zones in the microchip. For specific detection of biomarkers, that is, labels that are specific to certain biomolecules or cell types, a surface pull-down approach is typical. Here, the surface of a detection zone is coated with a chemical rearrangement that binds specifically to one or more biomarkers in question (see Chapter 7). Once immobilized, the biological material can then be subjected to a range of biophysical measurements to detect its presence. These are all techniques that have been discussed in the previous chapters of this book.
Fluorescence detection can be applied if the biomarker can be fluorescently labeled. To achieve fluorescence excitation, devices can utilize the photonics properties of the silicon-based flow-cell substrate, for example, photonic waveguiding to enable excitation light to be guided to the detection zone, photonic bandgap filtering to separate excitation light from fluorescence emissions, and smart designs of microfabricated photonic surface geometries to generate evanescent excitation fields to increase the detection signal-to-noise ratio by minimizing signal detection from unbound biological material.
Nonfluorescence detection lab-on-a-chip biosensors are also being developed. These include detection metrics based on laser dark-field detection of nanogold particles, and label-free approaches such as evanescent field interferometry, surface plasmon resonance–type methods and Raman spectroscopy, and surface-enhanced Raman spectroscopy (see Chapter 3), also, using electrical impedance and ultrasensitive microscale quartz crystal microbalance resonators (see Chapter 6). Microcantilevers, similar to those used in AFM imaging (see Chapter 6), can similarly be used for biomolecule detection. Here, the surface of the microcantilever is chemically functionalized typically using a specific antibody. As biomolecules with specificity to the antibody bind to the cantilever surface, this equates to a small change in effective mass, resulting in a slight decrease in resonance frequency that can be detected. Typical microcantilevers have a resonance frequency of a few hundred kHz, with an associated quality factor (or Q factor) of typically 800–900. For any general resonator system, Q is defined as
where
- v0 is the resonance frequency
- Δv is the half-power bandwidth, which is thus ~1 kHz
For many microcantilever systems, changes of ~1 in a 1000 in v0 can be measured across the bandwidth range, equating to ~1 Hz that corresponds to a change in mass of 10−15 kg (or 1 picogram, pg). This may seem a small amount, but even for a large protein of ~100 kDa molecular weight, this is equivalent to the binding of ~106 molecules. However, a real advantage with this method involves using multiple cantilevers with different antibody coatings inside the chip device to enable a signature for the presence of a range of different biomolecules present in a sample to be built up. Improvements in high-throughput and signature detection can be made using a similar array strategy of multiple detection zones using other biophysical detection techniques beyond microcantilevers.
Mechanical signals are also emerging as valuable metrics for cell types in biosensing, for example, using AFM to probe the stiffness of cell membranes, and also, optical force tools such as the optical stretcher to measure cell elasticity (see Chapter 6). Cell mechanics change in disease states, though for cancer the dependence is complex since different types of cancers can result in either increasing or decreasing the cell stiffness and also may have different stiffness values at different stages in tumor formation.
The faithful interpretation of relatively small biomolecule signals from portable lab-on-a-chip devices presents problems in terms of poor stability and low signal-to-noise ratios. Improvements in interpretation can be made using smart computational inference tools, for example, Bayesian inference (see Chapter 8). Although signals from individual biomarkers can be noisy, integrating the combination of multiple signals from different biomarkers through Bayesian inference can lead to greatly improved fidelity of detection. Much of this computation can be done decoupled from the hardware of the device itself, for example, to utilize smartphone technology. This enables a reduction in both the size and cost of the device and makes the prospect of such devices emerging into clinics in the near future more of a reality.
A Holy Grail in the biosensing field is the ability to efficiently and cheaply sequence single molecules of DNA. For example, the so-called $1000 genome refers to a challenge set for sequencing technologies called next-generation sequencers, which combine several biophysical techniques to deliver a whole genome sequence for a cost of $1000 or less. The U.S. biotech company Illumina has such a machine that purports to do so, essentially by first fragmenting the DNA, binding the fragments to a glass slide surface, amplifying the fragments using PCR (see Chapter 7), and detecting different fluorescently labeled nucleotide bases tagged with four different dyes in these surface clusters. Bioinformatics algorithms are used to computationally stitch the sequenced fragments together to predict the full DNA sequence. This is similar to the original Sanger shotgun approach for DNA sequencing, which generated DNA fragments but then quantified sequence differences by running the fragments on gel electrophoresis. However, the combination of amplification, clustering, and fluorescence-based detection results in far greater high throughput (e.g., one human genome sequenced in a few days). However, the error rate is ca. 1 in 1000 nucleotides, which may seem small but in fact results in 4 million incorrectly predicted bases in a typical genome, so there is scope for improvement.
A promising new type of sequencing technology uses ion conductance measurements through engineered nanopores, either solid state of manufactured from protein adapters such as α-hemolysin (see Chapter 6). For example, in 2012, the UK biotech company Oxford Nanopore released a disposable sequencing device using such technology that could interface with a PC via a USB port and which cost less than $1000. The device had a stated accuracy of ~4%, which makes it not sufficiently precise for some applications, but even so with a capability to sequence DNA segments up to ~1 million base pairs in length, this represents a significant step forward.
A promising area of smart in vivo diagnostics involves the use of synthetic biological circuits inside living cells. For example, such methods can in principle turn a cell into a biological computer that can detect changes to its environment, record such changes in memory composed of DNA, and then stimulate an appropriate cellular response, for example, send a signal to stop a cell from producing a particular hormone and/or produce more of another hormone, or to stimulate apoptosis (i.e., programmed cell death) if a cancer is detected.
One of the most promising emerging next-generation sequencing technologies is single-cell sequencing, which we discussed briefly in Chapter 7. Here, advanced microfluidics can be used to isolate a single cell on the basis of some biophysical metric. This metric is often, but not exclusively, fluorescence output from the labeling of one or more specific biomolecules in that cell, in much the same way as cells in standard fluorescence-assisted cell sorting (FACS) are isolated (see Chapter 3). The key differences here, however, are sensitivity and throughput. Single-cell sequencing demands a greater level of detection sensitivity to detect sometimes relatively small differences between individual cells, and the method is therefore intrinsically lower throughput than standard FACS since the process involves probing the biophysical metric of individual cells computationally more intensively.
For example, an individual cell may potentially be probed using single-molecule precise fluorescence imaging to infer the copy number of a specific fluorescently labeled biomolecule in that cell using a step-wise photobleaching of the fluorescent dye (see Chapter 8). That one cell can then be isolated from the rest of the population using advanced microfluidics, for example, using piezo microvalves or potentially even optical tweezers (see Chapter 6) to shunt the cell into a separate region of the smart flow cell. At this stage, the cell could, in principle, then be grown to form a clonal culture and subjected to standard bulk level sequencing technologies; however, the issue here is that such a cell population is never entirely “clonal” since there are inevitably spontaneous genetic mutations that occur at every cell division. A more definitive approach is to isolate the DNA of the one single cell and then amplify this using PCR (see Chapter 7). However, the mass of DNA from even a relatively large cell such as a human cell is just a few picograms (i.e., pg, or 10−12 g), which is at the very low end of copying accuracy for PCR, and so DNA replication errors during PCR amplification are much more likely with current technology available. Even so, single-cell sequencing offers genuine potential to bridge the phenotype to genotype gap. The real goal here in terms of personalized healthcare is to develop methods of very early-stage diagnosis of diseases and genetic disorders on the basis of detecting just a single cell from an individual patient sample.
Lower technology biophysics solutions to personalized diagnostics are also emerging and are especially appealing due to their low cost but high potential gain. For example, a simple card-based origami optical microscope has been developed by researchers at the UC Berkeley called the Foldscope (Cybulski et al., 2014) that can be assembled from a few simple folds of card, using just one cheap spherical microlens and an LED, as a light source produces images of sufficient quality to identify a range of different microbial pathogens up to a magnification of ~2000. But it weighs just 8 g and costs only ~$1 to make. A motivation for this cheap and low-tech device is to enable earlier diagnosis of microbial infection of patients in developing countries that may have no rapid access to microbial laboratory facilities.
9.4.2 Nanomedicine
The use of bionanotechnology applied to medicine is already emerging at the level of targeted drug binding, for example, to develop pharmaceutical treatments that destroy specific diseased cells such as those of cancers through the use of specific binding. These include radioactive nanoparticles coated with specific antibody probes to act as “killer” probes. Specific aptamers are used (see Chapter 7) to block key processes in specific diseases. Aptamers have an important advantage over molecular recognition technologies in evoking a minimal immune response, unlike the closest competing technology of antibody–antigen binding for which many antibodies evoke strong immunogenic reactions at relatively small doses. Targeted binding can also be valuable for the visualization of diseased tissue (e.g., antibody-tagged QDs can specifically bind to tumors and assist in the discrimination between healthy and nonhealthy cellular material).
Bionanotechnology is also being applied to assist in greater personalization of targeted drug delivery, that is, increasing the specificity and efficacy of drug actually being internalized by the cells in which they are designed to act. Established techniques in this area include the delivery of certain drug compounds into specific cell types by piggybacking on the normal process of endocytosis by which eukaryotic cells internalize extracellular material (see Chapter 2). Other emerging targeted delivery tools involve synthetic biological 3D nanostructures, for example, made from DNA, to act as molecular cages to enable the efficient delivery of a variety of drugs deep into a cell while protecting it from normal cellular degradation processes before it is released to exert its pharmacological effect.
Exciting nanomedicine developments also include bionanoelectric devices to interface with nerve and muscle tissue, such as in the brain and the heart. Devices used in cellular repair are sometimes referred to as nanoscale robots, or nanobots. Much recent media coverage concerning nanobots has involved speculation over the terrifying implications were they to go wrong. Such as consuming the entire Earth or at the very least turning it into a gray goo. However, the realistic state of the art in nanobot technology is still at a technically challenging stage; to get even natural nanoscale machines to work unmodified outside of their original biological function, let alone to generate de novo molecular machines that can be programmed by the user to perform cellular tasks, is hard enough, as any veteran student in this area of biophysics will attest!
The most promising emerging area of nanomedicine currently involves methods to facilitate tissue regeneration. This can be achieved through the use of biomimetic materials and the application of stem cells. Stem cells in multicellular eukaryotic organisms are cells that have not yet differentiated. Differentiation is not to be confused with the mathematical term in calculus, but here is a biological process in which cells undergo morphological and biochemical changes in their life cycle to commit to being a specific cell type, for example, a nerve cell and a muscle cell. However, prior to this stage, cells are described as stem cells and can in principle differentiate into any cell type depending on external triggers involving both the external chemical environment and mechanical signals detected by the cell from the outside world. Thus, if stem cells are transplanted from an appropriate donor source, they can in principle replace damaged tissue. In some countries, including the United States, there are still some levels of ongoing ethical debate as to the use of stem cells as a therapeutic aid to alleviate human suffering.
The development of biomimetic structures as replacements for damaged/diseased tissues has experienced many successes, such as materials either directly replace the damaged tissue and/or act as a growth template to permit stem cells to assemble in highly specific regions of space to facilitate the generation of new tissues. Biomimetic tissue replacement materials focus largely on being mimics for the structural properties of the healthy native tissue, for example, hard structural tissues such as bone and teeth and also softer structural extracellular matrix material such as collagen mimics.
Biocompatible inorganic biomimetics has focused on using materials that can be synthesized in aqueous environments under physiological conditions that exhibit chemical and structural stability. These particularly include noble metals such as gold, platinum, and palladium, as well as metal oxide semiconductors such as zinc oxide and copper(I) oxide, but also chemically inert plastics such as polyethylene, which benefit from having a low frictional drag while being relatively nonimmunogenic, and also some ceramics, and so all have applications in joint replacements. Inorganic surfaces are often precoated with short sequence peptides to encourage binding of cells from surrounding tissue.
Collagen is a key target for biomimetization. It provides a structural framework for the connective tissues in the extracellular matrix (see Chapter 2) as well as plays a key role in the formation of new bone tissue from bone producing cells (called osteoblasts) embedded in the extracellular matrix. Chemically modifying collagen, for example, by generating multiple copies of a cell binding domain, can increase the rate at which new bone growth occurs. This effect can be characterized using a range of biophysical techniques such as confocal microscopy and SEM in vitro. Thus, modified collagen replacement injected into the connective tissue of a patient suffering from a bone depletion disease into local regions of bone depletion, detected and quantified using x-ray and CT imaging in vivo, can act as a biomimetic microenvironment for osteoblasts to stimulate the regeneration of new bone tissue.
Mimicking the naturally porous and fibrous morphology of the extracellular matrix can also be utilized in biomimetization of tissues and organs. Some biomimetic tissues can be engineered in the absence of an artificial scaffold too, for example, skeletal muscle has been engineered in vitro using stem cells and just providing the current cellular and extracellular biochemical triggers; however, an artificial scaffold in general improves the efficiency of stem cells ultimately differentiating into regenerated tissues. For example, artificial nanofiber structures that mimic the native extracellular matrix can stimulate the adhesion of a range of different cell types and thus act as tissue-engineered scaffolds for several different tissues, which interface directly with the extracellular matrix, including bone, blood vessels, skin, muscles (including the heart muscle), the front surface of the eye (known as the cornea), and nerve tissue. Active research in this area involves the development of several new biohybrid/non-biohybrid materials to use as nanofiber scaffolds. Modification of these nanofibers involves chemically functionalizing the surface to promote binding of bioactive molecules such as key enzymes and/or various important drugs.
In wounds, infections, and burn injuries, skin tissue engineering using biomimetics approaches can be of substantial patient benefit. Nanofiber scaffolds can be both 2D and 3D. These can stimulate adhesion of injected stem cells and subsequently growth of new skin tissue. Similarly, nanobiomimetic tissue-engineered blood vessels can be used to promote adhesion of stem cells for stimulating growth of new blood vessels, which has been demonstrated in major blood vessels, such as the main artery of the aorta. This involves more complex growth of different types of cells than in skin, including both endothelial cells that form the structure of the wall of the artery as well as smooth muscle cells that perform an essential role in regulating the artery diameter and hence the blood flow rate. The efficacy of these nanofiber implants again can be demonstrated using a range of biophysics tools, here, for example, including Doppler ultrasound to probe the blood flow through the aorta and to use x-ray spectroscopy on implant samples obtained from animal model organisms ex vivo. Nanoscale particles and self-assembled synthetic biological nanostructures also have potential applications as scaffolds for biomimetic tissue.
9.4.3 Designer Drugs Through In Silico Methods
Bioinformatics modeling and molecular simulation tools (see Chapter 8) can now be applied directly to problems of screening candidate new drugs on their desired targets to enable the so-called in silico drug design. These simulation methods often combine ab initio with classical simulation tools to probe the efficacy of molecular docking of such candidate drugs. Such virtual screening of multiple candidate drugs can provide invaluable help in homing in on the most promising of these candidates for subsequent experimental testing.
The results of these experimental assays, many of which involve biophysics techniques discussed previously in this book, can then be fed back into refined computational modeling, and the process is iterated. Similarly, however, undesirable interactions between candidate new drugs and other cellular machinery benefit from in silico modeling approaches, for example, to simulate toxicity effects through detrimental interactions with biomolecules that are not the primary targets of the drug.
9.5 Extending Length and Time Scales to Quantum and Ecological Biophysics
Established biophysical tools have focused mainly on the broad length scale between the single molecule and the single cell. However, emerging techniques are being developed to expand this length scale at both extremes. At the high end, this includes methods of investigating multiple cells, tissues, and even large whole organisms of animals and plants. Beyond this organismal macroscopic length scale is a larger length scale concerning populations of organisms, or ecosystems, which can be probed using emerging experimental and theoretical biophysical methods. In addition, there are also biophysical investigations that are being attempted at the other end of the length scale, for far smaller lengths and times, in terms of quantum biology effects.
9.5.1 Quantum Biology
Quantum mechanical effects are ubiquitous in biology. For example, all molecular orbitals have an origin in quantum mechanics. The debate about quantum biology, however, turns on this simple question:
Does it matter?
Many scientists view “everyday” quantum effects as largely trivial. For example, although the probability distribution functions for an electron’s positions in time and space operate using quantum mechanical principles, one does not necessarily need to use these to predict the behavior of interacting atoms and molecules in a cellular process. Also, many quantum mechanical effects that have been clearly observed experimentally have been at low temperatures, a few Kelvin at most above absolute zero, suggesting that the relatively enormous temperatures of living matter on an absolute Kelvin scale lies in the domain of classical physics, hence the argument that quantum effects are largely not relevant to understanding the ways that living matter operates.
However, there are some valuable nontrivial counterexamples in biology that are difficult to explain without recourse to the physics of quantum mechanics. The clearest example of these is quantum tunneling in enzymes. The action of many enzymes is hard to explain using classical physics. Enzymes operate through a lowering of the overall free energy barrier between biochemical products and reactants by deconstructing the overall chemical reaction into a series of small intermediate reactions, the sum of whose free energy barriers is much smaller than the overall free energy barrier. It is possible in many examples to experimentally measure the reaction kinetics of these intermediate states by locking the enzyme using genetic and chemicals methods. Analysis of the reaction kinetics, however, using classical physics in general fails to explain the rapid overall reactions rates, predicting a much lower overall rate by several orders of magnitude.
The most striking example is the electron transport carrier mechanism of oxidative phosphorylation (OXPHOS) (see Chapter 2). During the operation of OXPHOS, a high-energy electron is conveyed between several different electron transport carrier enzymes, losing free energy at each step that is in effect siphoned off to be utilized in generating the biomolecule ATP that is the universal cellular energy currency. From a knowledge of the molecular structures of these electron transport carriers, we know that the shortest distance between the primary electron donor and acceptor sites is around ~0.2–0.3 nm, which condensed matter theory from classical physics is equivalent to a Fermi energy level gap that is equivalent to ~1 eV. However, the half reaction 2H+ + 2e−/H2 has a reduction potential of ca. −0.4 eV. That is, to transfer an electron from a donor to a proton acceptor, which is the case here that creates atomic hydrogen on the electron acceptor protein, results in a gain in electron energy of ~0.4 eV, but a cost in jumping across the chasm of 0.2–0.3 nm of ~1 eV. In other words, the classical prediction would be that electron transfer in this case would not occur, since it would imply a kinetic energy for the electron during the transition equivalent to ca. −0.6 eV, which is negative and thus forbidden.
However, experimentally it is known that electrons undergo these transitions (you are alive while reading this book, for example… one hopes…), and one explanation for these observations is that the electrons undergo quantum tunneling between the donor and acceptor sites, over a rapid time scale predicted to be ~10 fs (i.e., ~10−14 s). Quantum tunneling is also predicted to occur over longer length scales between secondary donor/acceptor sites; however, even though the time scale of tunneling transitions is within reach of the temporal resolution of electron spectroscopy measurements, no definitive experiments, at the time of writing of this book, have yet directly reported individual quantum tunneling events between electron transport carrier proteins in OXPHOS.
In a vacuum, quantum tunneling over such long distances would be highly improbable. However, in proteins, such as the electron transport carriers used in OXPHOS, the intervening soft-matter medium facilitates quantum tunneling by providing lower-energy virtual quantum states, which in effect reduce the overall height of the tunneling energy barrier, significantly increasing the physiological tunneling rates. The question is then not whether quantum tunneling is a component of the electron transport mechanism—it clearly is. Rather, it is whether these proteins evolved to utilize quantum tunneling as a selective advantage to the survival of their cell/organism host from the outset (see Chapter 2), or if the drivers of evolution were initially more aligned with classical physics with later tunneling capability providing a significant advantage. In several ways, one could argue that it is remarkable that the entire biological energy transduction machinery appears to be based on this quantum mechanical phenomenon of tunneling, given that much of biology does not require quantum mechanics at all.
A second interesting biological phenomenon, which is difficult to explain using classical physics, is the fundamental process by which plants covert the energy from sunlight into trapped chemical potential energy embedded in sugar molecules, the process of photosynthesis (see Chapter 2). Photosynthesis utilizes the absorption of photons of visible light by light-harvesting complexes, which are an array of protein and chlorophyll molecules typically embedded into organelles inside plant cells called “chloroplasts,” expressed in high numbers to maximize the effective total photon absorption cross-sectional area. Since the early twenty-first century, there has been experimental evidence for coherent oscillatory electronic dynamics in these light-harvesting complexes, that is, light-harvesting complexes in an extended array, which are all in phase with regard to molecular electronic resonance.
When initially observed, it was tempting to assign this phenomenon to quantum coherence, a definitive and nontrivial quantum mechanical phenomenon by which the relative phases of the wave functions of particles, electrons in this case, are kept constant. However, these oscillation patterns alone are not sufficient evidence to indicate quantum mechanical effects. For example, the effect can be modeled by classical physics as one of excitonic coupling to generate the appearance of coherence beating of the electronic excitation states across an array of light-harvesting complexes.
It is only relatively recently that more promising evidence has emerged for room temperature quantum coherence effects in photosynthesis (O’Reilly and Olaya-Castro, 2014). When the vibrations of neighboring chlorophyll molecules match the energy difference between their electronic transitions, then a resonance effect can occur, with a by-product of a very efficient energy exchange between these electronic and vibrational modes. If the vibrational energy is significantly higher than the thermal energy scale for energy transitions equivalent to ~kBT, then this exchange, if observed experimentally, cannot be explained classically, but can be explained by modeling the exchange as due to discrete quanta of energy.
Experiments to probe the electronic–vibrational resonance in chlorophyll molecules have been performed in vitro using time-resolved femtosecond electron spectroscopy. Analysis of these data indicates a so-called negative joint probability for finding the chlorophyll molecules within certain specific relative positions and momenta. Classical physics predicts that these probability distributions are always positive, and therefore this represents a clear signature of quantum behavior.
That being said, the absolute thermal energy scale of ~kBT at 300 K is still much higher than that expected for likely quantum coherence effects by several orders of magnitude. In other words, at ambient “room” temperature of biology, one might expect the surrounding molecular chaos in the cell to annihilate any quantum coherence almost instantly. But recent simulations suggest that quantum coherence may still result in a level-broadening effect of the free energy landscape—flattening out local minima due to thermal fluctuation noise thereby increasing the overall efficiency of energy transport—possibly by up to a factor of two.
A related recent study involves quantum coherence observed in the enzyme lysozyme (discussed previously in Chapter 5). In this study (Lundholm et al., 2015), the researchers found evidence at very low ~1 K temperatures for coupled electrical dipole states in crystals of lysozyme following the absorption of terahertz radiation. This observation was consistent with a previously hypothesized but hitherto undetected state of matter called a “Fröhlich condensate,” a vibrational ground state of dielectric matter analogous to the Bose–Einstein condensate on bosons, in which quantum coherence results in an extended state of several coupled electric dipoles from different molecules over a long length scale equivalent in effect to the whole crystal.
Although highly speculative, theoretical physicist Roger Penrose and anesthesiologist Stuart Hameroff (Penrose et al., 2011) had previously hypothesized that microtubules inside cells might function as quantum computing elements, driven by quantum coherence over the long length scales of microtubule filaments. Normally, a wave function, as a superposition of all quantum states, is expected to collapse upon an interaction between the quantum system and its environment (i.e., we measure it). However, in this system the collapse was hypothesized not to occur until the quantum superpositions become physically separated in space and time, a process known as objective reduction, and when such quantum coherence collapses, then an instant of consciousness occurs. The physical cause of this hypothetical coherence in microtubules was speculated by Penrose as being due to Fröhlich condensates (Fröhlich, 1968). Previously, experimental studies failed to identify Fröhlich condensates, so this recent study, although still hotly debated, may serve to propagate this speculation of quantum-based consciousness a little further. However, at present, it is going too far to make a link between quantum mechanics and consciousness; the evidence is enormously thin. But the key thing here is that the Fröhlich condensate has been a controversy for over half a century, and now if these new experimental results support the Fröhlich hypothesis, it means that biological systems may have the potential to show quantum mechanical coherence at room temperature. This would clearly influence the organization of many biological processes and the transmission of information, in particular.
A fourth, and perhaps more mysterious, example of nontrivial quantum biology is the geonavigation of potentially many complex multicellular organisms. There is good experimental evidence to support the theory of magnetoreception in several organisms. This is the sense that allows certain organisms to detect external magnetic fields to perceive direction/altitude/location, and ultimately use this to navigate. For example, Magnetospirilum bacteria are magnetotaxic (i.e., their direction of swimming is affected by the direction of an external magnetic field), common fruit flies appear to be able to “see” magnetic fields, homing pigeons appear to respond to magnetic fields as do some mammals such as bats, and similarly salmon, newts, turtles, lobsters, honeybees even certain plants such as the model organism mouse ear cress (see Chapter 7) respond in growth direction to magnetic fields, though arguably in all of the experimental studies tried to date the size of the artificially generated magnetic field used is much larger than the native Earth’s magnetic field by an order of magnitude or more.
Two competing models for magnetoreception in birds use either classical physics in alluding to a magnetic particle (the presence of small magnetic particles of magnetite is found in the heads of many migratory birds) or a quantum mechanical model based on the generation of radical pairs. The latter theory implicates a molecule called cryptochrome—a light-sensitive protein that absorbs a blue light photon to generate two radical pairs (molecules with a single unpaired electron).
This effect has been studied most extensively in the migratory patterns of a bird Erithacus rubecula (known more commonly as the European robin, the one you have probably seen yourself, if not in the flesh, then from its ubiquitous images on Christmas cards). Evidence has grown since the original study published in 2004 (Ritz et al., 2004) that each robin potentially utilizes a chemical compass in the form of cryptochrome that is expressed in certain cells in the retinas of the birds’ eyes (cryptochromes have also been found in photoreceptor nerve cells in the eyes of other birds and insects and in some plant cells and bacteria).
Cryptochrome contains a flavin cofactor called “FADH” (the hydrogenated form of flavin adenine dinucleotide, the same cofactor as occurs at various stages in Krebs tricarboxylic acid cycle; see Chapter 2). One hypothesis is that molecular oxygen can enter a molecular binding pocket of the cryptochrome molecule, and a radical pair can then be formed upon the absorption of a single photon of blue light consisting of FADH· and the molecular oxygen superoxide
If the radical pair is in its singlet state, the unpaired electron from the superoxide radical may transfer to the FADH radical, forming a singlet (FADH−A + O2) state, which has lower free energy and is magnetically insensitive (note that this electron transfer is not possible from the triplet state of the radical pair since this would not conserve total spin). That is, the radicals are self-quenched. However, if the superoxide radical escapes from the molecular pocket before this quenching electron transfer occurs, then this can result in an extended lifetime of the magnetically sensitive radical states for as long as the spins between the electrons of the FADH· and the
If the singlet/triplet radical products have sufficiently long quantum coherence times, they may therefore be biologically detectable by as a chemical compass—in essence, the entanglement would imply that the extent of any coupling observed depends on the local magnetic field. One hypothesis is that the superoxide formed in the radical pair is particularly important in magnetoreception. This is because the oxygen radical does not exhibit hyperfine coupling, and so any observed coupling is a metric of the external magnetic field.
Quantum entanglement–based magnetoreception is speculative at several levels. First, it implies that modulation of the reaction products by a magnetic field would lead to a behavioral modulation of the bird’s flight through, presumably, the bird’s sense of vision combined with moving its head to scan the B-field landscape, for example, generating brighter or darker regions on the bird’s retina. But there is no clear experimental evidence for this effect. Also, it is unclear specifically where in the bird’s eye this putative radical pair reaction would actually takes place. It may well be that high-resolution biophysical structural imaging tools, such as AFM, may provide some future insight here, at least into mechanisms of free radical formation upon light absorption.
Most challenging to this theory, however, are estimates that the entangled state would need to last >100 μs to have sufficient sensitivity for use a chemical compass given the low strength of the Earth’s B-field of ~5 mT. However, the longest entangled states observed to date experimentally in the laboratory have lifetimes of ~80 μs, seen in a special inorganic molecule from a class called endohedral fullerenes (or endofullerenes or simply fullerenes for short) known as “N@C60” that consists of a shell of 60 carbon atoms with a single nitrogen atom at the center and is highly optimized for extended quantum entanglement since the carbon shell provides a magnetic shield from randomized external magnetic fluctuations due to surrounding atoms, which would otherwise result in decoherence. So, currently, one would sensibly conclude that the speculation of quantum entanglement in cryptochrome molecule resulting in magnetoreception is interesting; however, the jury is definitely out!
9.5.2 From Cells to Tissues
Although the tools and techniques of biophysics have contributed to many well-documented studies at the level of single cells, in terms of generating significant insight into a range of biological processes when studied at the level of single, isolated cells, there is a paucity of reliable experimental data, which has the equivalent quality and temporal and spatial resolutions of isolated single cells. This is true for prokaryotic single-celled organisms such as bacteria, but also single-cell eukaryotic organisms such as yeast, as well as cultured single eukaryotic cells from multicellular organisms. The latter includes cells that often appear to operate as a single cell, for example, white blood cells called macrophages that are part of the immune response and operate by engulfing foreign pathogen particles. But also, for isolated cells that would normally be expressed among a population of other neighboring cells, such as in a tissue or organ, both in the case of normal cells and for diseases such as probing cells inside a cancer tumor.
This tight packing of cells is very important. Not only do cells experience chemical cues from other surrounding cells but also often very complex mechanical signals. An equally important point to note is that this is not just true for eukaryotic cells inside tissues/organs of complex multicellular organisms but also for microbial organisms such as yeast and bacteria that are described as being “unicellular.” This is because although such cells exhibit stages in their life cycles of being essentially isolated single cells, the majority of a typical cell’s life is actually spent in a colony of some sort, surrounded in close proximity by other cells, often of the same type though sometimes, as is the case in many bacterial biofilms, sharing a colony with several different bacterial species.
Investigation of cellular biophysical properties but in the context of many other neighboring cells presents technical challenges. The key biophysical techniques to use involve optical microscopy, typically various forms of fluorescence imaging, and mechanical force probing and measurement methods, such as AFM. The challenge for optical microscopy is primarily that of light microscopy imaging in “deep tissues,” namely, a heterogeneous spatial distribution in refractive index and increased scatter, photodamage, and background noise. However, as discussed previously (see Chapter 3), there are now technical strategies that can be applied to minimize these optical imaging issues. For example, the use of adaptive optics to counteract optical inhomogeneity, and methods such as multiphoton excitation fluorescence microscopy and light sheet imaging to minimize background noise and sample photodamage. Even, in fact, standard confocal microscopy has several merits here, though it lacks the imaging speed required to monitor many real-time biological processes. Similarly, one of AFM imaging’s primary technical weaknesses was in sample damage; however, with developments in “lighter touch” torsional AFM imaging, this problem can be minimized.
Biofilms present a particularly challenging health problem when coupled to microbial infection, in being very persistent due to their resistance against many antiseptic measures and antibiotic treatments. These are particularly problematic for applications of medical prosthetics, for example, infections on the surfaces of prosthetic joints and for regions of the body where the inside and outside world collide, for example, urinary tract infections on catheters and periodontitis in teeth and gums. One reason for this is that cells in the center of a biofilm are chemically protected by the neighboring outer cells and by slimy glycocalyx structures secreted by the cells. These are known as microbial extracellular polymeric substances (EPS), but these can also combine to form a composite gel with extracellular biopolymers such as collagen, which are produced by the host organism. This composite coat allows small solutes and gases to permeate but which form an effective barrier against many detergents, antiseptics, and antibacterial toxins such as antibiotics and also to penetration by white blood cells in the host organism immune response. There is therefore enormous potential to probe the various mechanisms of biofilm chemical defense using next-generation biophysical tools.
However, there is now emerging evidence that biofilms exhibit significant mechanical robustness. This compounds the difficulty in healthcare treatment of biofilm infections since they are often very resistant to mechanical removal. This is not just at the level of needing to brush your teeth harder, but presents issues in treating infections in vivo, since to completely eradicate a biofilm infection potentially needs a combination of killing outer cells and weakening outer biofilms structures to the extent that, for example, viscous drag forces for in vivo fluid flow might then be sufficient to completely dislodge a biofilm from the surface it is infecting. Experimental measurement of the mechanical shear stress failure levels for different biofilms using a range of biophysical force probe approaches (see Chapter 6) suggests that typical physiological fluid flow levels, for example, those found in blood and urine, are in general not sufficient to dislodge biofilms.
At a coarse-grained level of approximation, the mechanical properties of a biofilm can be modeled as that of a densely packed hydrogel. As discussed previously (see Chapter 8), the variation of elastic modulus of hydrogels varies as ~C2.25 where C is the concentration of the effective “biopolymer.” C here is more a metric for the local cell density in this case, and the implication is that under the tightly packed conditions inside a biofilm, the equivalent elastic modulus is very high. New methods to disrupt the EPS to reduce its mechanical robustness are under development currently, and a key feature of these studies is biophysical force probe investigations.
9.5.3 From Organisms to Ecosystems
An ecosystem is defined as the combination of a population of interacting individual organisms, whether of the same or different types, and of the environment in which these organisms reside. The connections between biophysics and ecological phenomena have only been directly investigated relatively recently, principally along the theme of ecomechanics. That is, how do the organisms in a population interact mechanically with each other and with their environment, and how do these mechanical interactions lead to emergent behaviors at the level of an ecosystem.
A number of model ecology systems have emerged to probe these effects. For example, the mechanics of mollusks clinging to rocks on a seabed. Modeling the mechanical forces experienced by a single mollusk is valuable of course; however, population-level modeling is essential here to faithfully characterize the system since the close packing of individual mollusks means that the effect on the local water flow due to the presence of any given mollusk will be felt by neighboring mollusks. In other words, the system has to be modeled at an ecomechanics level.
This level of organism fluid dynamics cooperativity is also exhibited by swimming organisms, for example, fish and swimming mammals such as whales create trailing vortices in the water as they move, which has the effect of sucking surrounding water into the wake of a swimmer. This in effect results in the local fluid environment being dragged into different marine environments by the swimmer. In other words, populations of large swimming organisms have an effect of increasing the mixing of sea water between different environments. This is relevant to other ecosystems since this could, for example, result in a spread in ocean acidification along migratory swimmer routes, which is greater than would be expected in the absence of this fluid drag effect.
There is also a sensible argument that this drift behavior in a school of fish results in greater hydrodynamic efficiency of the population as a whole, that is, by sticking close together, each individual fish exerts on average less energy, though a counterargument applies in that fish toward the front and edges of a school must expend more energy than those in the middle and at the back. Thus, for the theory to be credible, there would need to be something equivalent to a social mechanism of sharing the load, that is, fish change places, unless the fish at the front and edges benefit in other ways, for example, they will be closer to a source of food in the water. But in terms of fluid dynamics effects, this is essentially the same argument as rotating the order of cyclists in a team as they cycle together in a group.
Similar mechanical feedback is also exhibited in populations of plants. For example, the leaf canopies of trees result in difficult to predict emergent patterns in airflow experienced by other surrounding trees in a wood or forest population, sometimes extending far beyond nearest neighbor effects. This is important since it potentially results in complex patterns of rainfall over a population of trees and of the direction of dispersal of tree pollen.
Airflow considerations apply to the flocking of birds and the swarming of flies. However, here other biophysical effects are also important, such as visual cues of surrounding birds in the flock, potentially also audio cues as well. There is also evidence for cooperativity in fluid dynamics in swimmers at a much smaller length scale, for example, microbial swimmers such as bacteria. Under these low Reynolds numbers swimming conditions (see Chapter 6), the complex flow patterns created by individual microbial swimmers can potentially result in a local decrease in effective fluid viscosity ahead of the swimmer, which clearly has implications to microbial swarming at different cell densities, and how these potentially lead to different probabilities for forming microbial colonies from a population of free swimmers.
Other effects include the biophysical interactions between carbon dioxide in the atmosphere and water-based ecosystems. For example, increased levels of atmospheric carbon dioxide dissolve in the saltwater of the oceans and freshwater in rivers and lakes to result in increased acidification. This can feedback into reduced calcification of crustaceous organisms that possess external calcium carbonate shells. There is evidence that human-driven increases in atmospheric carbon dioxide (such as due to the burning of fossil fuels) can result in a local decrease in pH in the ocean by >0.1 pH unit, equivalent to an increase in proton concentration of >25%. This may have a dramatic detrimental effect on crustaceous organisms, which is particularly dangerous since marine plankton come into this category. Marine plankton are at the bottom of the ocean food chain, and so changes to their population numbers may have dramatic effects on higher organisms, such as fish numbers. Calcification also plays a significant role in the formation of coral reefs, and since coral reefs form the mechanical structure of the ecological environment of many marine species increased, ocean acidification may again have a very detrimental effect on multiple ecosystems at a very early stage in the food chain.
9.6 The Impact of AI, ML, and Deep Learning on Biophysics and the Physics of Life
Artificial Intelligence (AI) refers to the development and application of computer systems that can perform tasks that would normally require human intelligence, such as mimicking cognitive functions involved in learning, problem-solving, perception, and decision-making. They are particularly powerful at processing large data sets, recognizing and categorizing patterns in these, and using these patterns to make predictions. Machine learning (ML) is an important subset of AI that focuses on developing algorithms and models that can learn from data without being explicitly programmed. ML algorithms learn from patterns and gold-standard examples (or training data sets) to classify objects, identify correlations, and make predictions. Deep learning, a subset of ML, utilizes neural networks with multiple layers to process complex data and extract hierarchical representations.
It has, of course, had a significant impact on multiple fields, including the biophysics and the physics of life:
- Data analysis and modeling: AI algorithms can process vast amounts of experimental data, identify patterns, and extract valuable insights. In the physics of life, AI is used to analyze complex datasets obtained from experiments such as protein folding, molecular dynamics simulations, and gene expression studies. For example, AlphaFold developed by Google DeepMind in 2018 and the improved version AlphaFold2 released in 2020 (Jumper et al 2021) show potential for genuinely disruptive impact in enabling the prediction of the 3D structure of proteins from sequence data. Both versions utilize DL methods utilizing large-scale supervised training datasets from established experimental structural biology data, but AlphaFold2 incorporates an additional attention-based neural network architecture called the “transformer,” which allows for better modeling of longer-range interactions within proteins compared to the original version. The key potential is that it enables prediction of protein structures, which are very challenging to achieve using existing experimental techniques, such as membrane integrated proteins. AI models can also be developed to simulate and predict the behavior of complex biological systems, aiding in understanding and predicting emergent biological phenomena. AI can also be used to build accurate models for biophysical systems, such as protein folding, molecular interactions, and drug design. An excellent recent example is the application of AI methods to develop new, an entirely synthetic antibiotic (Liu et al., 2023), which is effective against the Gram-negative pathogen Acinetobacter baumannii, a superbug prevalent in many hospitals that exhibits multidrug resistance. Here, researchers first screened 7684 small molecules, consisting of 2341 off-patent drugs and 5343 synthetic compounds, to look for evidence of growth inhibition of A. baumannii in vitro. These were used to train a neural network, which was then used on a chemical library of 6680 molecules selected as proof-of-concept for its structural diversity and favorable antibacterial activities, to predict potential undiscovered candidates that would inhibit A. baumannii growth. Of these, 240 molecules showed promisingly high scores and were then subject to laboratory testing, with nine “priority molecules” ultimately whittled down to a top candidate of abaucin, an entirely new antibiotic with narrow-spectrum activity against A. baumannii. A particularly telling finding from this study was that once the training dataset was developed, the in silico screening of 6680 molecules top reduce down to 240 likely candidates took only ~90 minutes.
- Bioimage analysis and pattern recognition: AI excels in image analysis and pattern recognition tasks, which, as can be seen from the range of biophysics tools and techniques discussed in this book, are crucial in studying life and the physics of life. They can aid in big data tasks (i.e. those in which the data sets are too large/complex to be analysis by traditional data processing tools) such as recognition techniques to identify and cells and track them in real time, or to detect specific tissues or specific molecular structures in biological images, enabling the study of a range of biological processes at far more granular levels than was possible previously.
AI also shows clear promise in enabling general data-driven discovery by revealing previously hidden relationships from large-scale datasets and helping to identify non-intuitive correlations and patterns that may lead to new discoveries in the physics of life. This may serve to catalyze the generation of new hypotheses and new experimental designs and optimized protocols. As with all applications of AI, however, several challenges remain. Regarding biophysics and physics of life research, two of these are key. One is ethical, in that allowing non-human intervention in critical decision-making concerning new drug designs and biotech innovations could, for example, result in inventions which are potentially dangerous for unforeseen reasons, and potentially difficult to control since the AI optimization process is, at least at the time of writing, very largely a black box. The other is more nuanced but important issue comes down to aspects of performance. Ultimately, the output accuracy of any AI system is only as good as the training dataset used. An inevitable challenge will arise in the not-so-distant future whereby AI outputs themselves will be accepted as sufficiently gold-standard for training new models. But if these AI outputs have not been subjected to the rigorous experimental validation of the original training data, drift in output accuracy is inevitable. So, revolutionary as AI is for big data processing, there needs to be checks and balances in place.
9.7 Summary Points
- Systems biology coupled with biophysics enables significant scientific insight through coupling cutting-edge computation with experimental biophysics, often in native biological systems.
- Synthetic biology enables complex self-assembled nanostructures to be fabricated using biological material such as DNA, which have applications in nanomedicine and basic biophysics investigations.
- Biological circuits offer potential to design complex biocomputers inside living cells.
- Biophysics developments have enabled miniaturization of biosensors to facilitate lab-on-a-chip technologies for improved personalized healthcare diagnostics and treatment.
- Biophysics can extend into the quantum world and into whole ecosystems.
Questions
- 9.1 The surface area of a light-harvesting protein complex was estimated using AFM imaging to be 350 nm2. Sunlight of mean wavelength 530 nm and intensity equivalent to 4 × 1021 photons m−2 s−1 was directed onto the surface of cyanobacteria containing light-harvesting complexes in their cell membranes, whose energy was coupled to the pumping of protons across a cell membrane, with a steady-state protonmotive force of –170 mV. To be an efficient energy transfer, one might expect that the effective transfer time for transmembrane pumping of a single proton should be faster than the typical rotational diffusion time of a protein complex in the membrane of a few nanoseconds; otherwise, there could be energy dissipation away from the proton pump. Explain with reasoning whether this is an efficient energy transfer.
- 9.2 With specific, quantitative reference to length scales, rates of diffusion, and concentrations of nutrients, explain why a time-sampling strategy is more sensible for a bacterium than a space-sampling mechanism for chemotaxis.
- 9.3 Discuss the biological, chemical, and biophysical challenges to efficiently deliver and release a drug specifically to a given subcellular organelle that is caged inside a 3D DNA nanostructure?
- 9.4 What do biologists mean by “robustness” in the context of a biological circuit? Using an electrical circuit diagram approach, show how robustness can be achieved in principle using feedback. How can oscillatory behavior arise in such robust systems?
- 9.5 What is a transcriptor? How can multiple transcriptors be coupled to generate a bistable oscillator (i.e., an oscillating output in time between on and off states)?
- 9.6 If a particular single gene’s expression is in steady state in a spherical bacterial cell of 1 μm diameter such that there are a total of 50 repressor molecules in the cell, which can each bind to the gene’s promoter with a probability of 10% s−1, and the expressed protein can directly activate its own expression at a rate of one molecule per second, calculate the cellular concentration of the expressed protein in nM units stating any assumptions you make.
- 9.7 How is Schrödinger’s famous quantum mechanical wave equation, which governs the likelihood for finding an electron in a given region of space and time, related to the probability distribution function of a single diffusing biological molecule? Discuss the significance of this between the life and physical sciences.
- 9.8
A synthetic DNA molecule was designed to be used for optical data transmission by turning the DNA into a molecular photonics wire comprising five different neighboring dye molecules, with each having an increasing peak wavelength of excitation from blue, green, yellow, orange through to red. Each dye molecule was conjugated in sequence to accessible sites of the DNA, which was tethered from one end of a glass coverslip. Each dye molecule was spaced apart by a single-DNA helix pitch. The mean Förster radius between adjacent FRET pairs was known to be ~6 nm, all with similar absorption cross-sectional areas of ~10−16 cm2.
- When a stoichiometrically equal mix of the five dyes was placed in bulk solution, the ratio of the measured FRET changes between the blue dye and the red dye was ~15%. How does that compare with what you might expect?
- Similar measurements on the single DNA-dye molecule suggested a blue-red FRET efficiency of ~90%. Why is there such a difference compared to the bulk measurements?
- 9.9 For the example data transmission synthetic biomolecule of Question 9.8, a blue excitation light of wavelength 473 nm was shone on the sample in a square wave of intensity 3.5 kW cm−2, oscillating between on and off states to act as a clock pulse signature.
- If the thermal fluctuation noise of the last dye molecule in the sequence is roughly ~kBT, estimate the maximum frequency of this clock pulse that can be successfully transmitted through the DNA-dye molecule, assuming that the emission from the donor dye at the other end of the DNA molecule was captured by an objective lens of NA 1.49 of transmission efficiency 80%, split by a dichroic mirror to remove low-wavelength components that captured 60% of the total fluorescence, filtered by an emission filter of 90% transmission efficiency, and finally imaged using a variety of mirrors and lenses of very low photon loss (<0.1%) onto an electron-multiplying charge-coupled device (CCD) detector of 95% efficiency.
- How would your answer be different if a light-harvesting complex could couple to the blue dye end of the photonic wire? (Hint: see Heilemann et al., 2004.)
- 9.10 The integrated intensity for a single molecule of the yellow fluorescent protein mVenus was first estimated to be 6100 ± 1200 counts (±standard deviation) on a camera detector in a single-molecule fluorescence microscope. Each protein subunit in the shell of a carboxysome was labeled with a single molecule of mVenus with biochemical experiments suggesting that the distribution of stoichiometry values of these specific carboxysomes was Gaussian with a mean of 16 and standard deviation sigma width of 10 subunit molecules. The initial integrated fluorescence intensity of a carboxysome population numbering 1000 carboxysomes was measured in the same fluorescence microscope under the same conditions as was used to estimate the single-molecule brightness of mVenus, with the stoichiometry of each carboxysome estimated by dividing the initial fluorescence intensity obtained from a single exponential fit to the photobleach trace (see Chapter 8) by the single-molecule fluorescence intensity for mVenus. Estimate with reasoning how many carboxysomes have a calculated stoichiometry, which is precise to a single molecule.
- 9.11 Discuss the key general technical scientific challenges to developing a lab-on-chip biosensor for use in detecting early-stage bacterial infections that are resistant to antibiotics and strategies to overcome them.
- 9.12 If there are no “preferred” length and time scales in biology, with complex and multidirectional feedback occurring across multiple scales, then what can the isolated study of any small part of this milieu of scales, for example, at a single-molecule level, a cellular level, a tissue level, a whole organism level, or even at a whole ecosystem level, actually tell us?
References
Key Reference
- Rothemund, P.W.K. (2006). Folding DNA to create nanoscale shapes and patterns. Nature 44:297–302.
More Niche References
- Agapakis, C.M. et al. (2011). Towards a synthetic chloroplast. PLOS One 6:e18877.
- Aryee, P. 2021–22. 30 animals that made us smarter. Podcast from BBC World Service.
- Bonnet, J. et al. (2013). Amplifying genetic logic gates. Science 340:599–603.
- Cybulski, J.S., Clements, J., and Prakash, M. (2014). Foldscope: Origami-based paper microscope. PLOS One 9:e98781.
- Feynman, R.P. (1959). “There’s plenty of room at the bottom” lecture. Transcript deposited at Caltech Engineering and Science Library, Vol. 23(5), February 1960, pp. 22–36, California Institute of Technology, Pasadena, CA.
- Feynman, R.P. (1963). The Feymann Lectures on Physics, Vol. I. California Institute of Technology, Pasadena, CA, pp. 1–2.
- Friedmann, H.C. (2004). From “butyribacterium” to “E. coli”: An essay on unity in biochemistry. Perspect. Biol. Med. 47:47–66.
- Fröhlich, H. (1968). Long-range coherence and energy storage in biological systems. Int. J. Quant. Chem. 2:641–649.
- Goodman, R.P. et al. (2005). Rapid chiral assembly of rigid DNA building blocks for molecular nanofabrication. Science 310:1661–1665.
- Heilemann, M. et al. (2004). Multistep energy transfer in single molecular photonic wires. J. Am. Chem. Soc. 126:6514–6515.
- Hiratsuka, Y. et al. (2006) A microrotary motor powered by bacteria. Proc. Natl. Acad. Sci. USA 03:13618–13623.
- Jumper, J. et al. (2021). Highly accurate protein structure prediction with AlphaFold. Nature 596:583–589.
- Kinosita, S. et al. (2008). Physics of structural colors. Rep. Prog. Phys. 71:076401.
- Liu, G. et al, (2023). Deep learning-guided discovery of an antibiotic targeting Acinetobacter baumannii. Nature Chem. Biol. doi: 10.1038/s41589-023-01349-8.
- Lundholm, I.V. et al. (2015). Terahertz radiation induces non-thermal structural changes associated with Fröhlich condensation in a protein crystal. Struct. Dyn. 2:054702.
- O’Reilly, E.J. and Olaya-Castro, A. (2014). Non-classicality of the molecular vibrations assisting exciton energy transfer at room temperature. Nat. Commun. 5:3012.
- Pan, C. et al. (2008). Nanowire-based high-performance “micro fuel cells”: One nanowire, one fuel cell. Adv. Mater. 20:1644–1648.
- Penrose, R. et al. (2011). Consciousness and the Universe: Quantum Physics, Evolution, Brain & Mind. Cosmology Science Publishers, Center for Astrophysics, Harvard-Smithsonian, Cambridge, MA.
- Ritz, T. et al. (2004). Resonance effects indicate a radical-pair mechanism for avian magnetic compass. Nature 429:177–180.
- Seeman, N.C. (1982). Nucleic-acid junctions and lattices. J. Theor. Biol. 99:237–247.
- Taniguchi, N. (1974). On the basic concept of “nano-technology”. Proceedings of the International Conference on Production Engineering, Part II, Japan Society of Precision Engineering, Tokyo, Japan.
- Turberfield, A.J. (2011). DNA nanotechnology: Geometrical self-assembly. Nat. Chem. 3:580–581.